The functional form of value normalization in human reinforcement learning
Curation statements for this article:-
Curated by eLife

eLife assessment
It is well established that valuation and value-based decision making is context-dependent, but the exact form of normalization has remained an open question. This study provides compelling evidence that values during reward learning are normalized based on the range of available values. These findings will be important for researchers interested in reward learning and decision-making.
This article has been Reviewed by the following groups
Discuss this preprint
Start a discussion What are Sciety discussions?Listed in
- Evaluated articles (eLife)
Abstract
Reinforcement learning research in humans and other species indicates that rewards are represented in a context-dependent manner. More specifically, reward representations seem to be normalized as a function of the value of the alternative options. The dominant view postulates that value context-dependence is achieved via a divisive normalization rule, inspired by perceptual decision-making research. However, behavioral and neural evidence points to another plausible mechanism: range normalization. Critically, previous experimental designs were ill-suited to disentangle the divisive and the range normalization accounts, which generate similar behavioral predictions in many circumstances. To address this question, we designed a new learning task where we manipulated, across learning contexts, the number of options and the value ranges. Behavioral and computational analyses falsify the divisive normalization account and rather provide support for the range normalization rule. Together, these results shed new light on the computational mechanisms underlying context-dependence in learning and decision-making.
Article activity feed
-

-

Author Response
Reviewer #1 (Public Review):
It is well established that valuation and value-based decision-making is context-dependent. This manuscript presents the results of six behavioral experiments specifically designed to disentangle two prominent functional forms of value normalization during reward learning: divisive normalization and range normalization. The behavioral and modeling results are clear and convincing, showing that key features of choice behavior in the current setting are incompatible with divisive normalization but are well predicted by a non-linear transformation of range-normalized values.
Overall, this is an excellent study with important implications for reinforcement learning and decision-making research. The manuscript could be strengthened by examining individual variability in value normalization, …
Author Response
Reviewer #1 (Public Review):
It is well established that valuation and value-based decision-making is context-dependent. This manuscript presents the results of six behavioral experiments specifically designed to disentangle two prominent functional forms of value normalization during reward learning: divisive normalization and range normalization. The behavioral and modeling results are clear and convincing, showing that key features of choice behavior in the current setting are incompatible with divisive normalization but are well predicted by a non-linear transformation of range-normalized values.
Overall, this is an excellent study with important implications for reinforcement learning and decision-making research. The manuscript could be strengthened by examining individual variability in value normalization, as outlined below.
We thank the Reviewer for the positive appreciation of our work and for the very relevant suggestions. Please find our point-by-point answer below.
There is a lot of individual variation in the choice data that may potentially be explained by individual differences in normalization strategies. It would be important to examine whether there are any subgroups of subjects whose behavior is better explained by a divisive vs. range normalization process. Alternatively, it may be possible to compute an index that captures how much a given subject displays behavior compatible with divisive vs. range normalization. Seeing the distribution of such an index could provide insights into individual differences in normalization strategies.
Thank you for pointing this out, it is indeed true that there is some variability. To address this, and in line with the Reviewer’s suggestion, we extracted model attributions per participant on the individual out-of-sample log-likelihood, using the VBA_toolbox in Matlab (Daunizeau et al., 2014). In experiment 1 (presented in the main text), we found that the RANGE model accounted for 79% of the participants, while the DIVISIVE model accounted for 12%. The relative difference was even higher when including the RANGEω model in the model space: the RANGE and RANGEω models account for a total of 85% of the participants, while the DIVISIVE model accounted only for 5%.
In experiment 2 (presented in the supplementary materials), the results were comparable (see Figure 3-figure supplement 3: 73% vs 10%, 83% vs 2%).
To provide further insights into the behavioral signatures behind inter-individual differences, we plotted the transfer choice rates for each group of participants (best explained by the RANGE, DIVISIVE, or UNBIASED models), and the results are similar to our model predictions from Figure 1C:
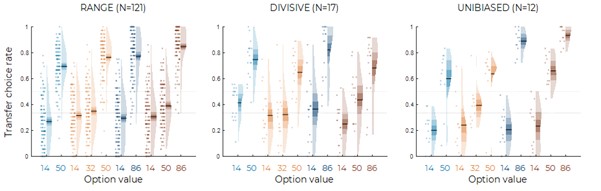
Author Response Image 1. Behavioral data in the transfer phase, split over participants best explained by the RANGE (left), DIVISIVE (middle) or UNBIASED (right) model in experiment 1 (A) and experiment 2 (B) (versions a, b and c were pooled together).
To keep things concise, we did not include this last figure in the revised manuscript, but it will be available for the interested readers in the Rebuttal letter.
One possibility currently not considered by the authors is that both forms of value normalization are at work at the same time. It would be interesting to see the results from a hybrid model. R1.2 Thank you for the suggestion, we fitted and simulated a hybrid model as a weighted sum between both forms of normalization:
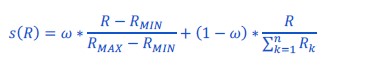
First, the HYBRID model quantitatively wins over the DIVISIVE model (oosLLHYB vs oosLLDIV : t(149)=10.19, p<.0001, d=0.41) but not over the RANGE model, which produced a marginally higher log-likelihood (oosLLHYB vs oosLLRAN : t(149)=-1.82, p=.07, d=-0.008). Second, model simulations also suggest that the model would predict a very similar (if not worse) behavior compared to the RANGE model (see figure below). This is supported by the distribution of the weight parameter over our participants: it appears that, consistently with the model attributions presented above, most participants are best explained by a range-normalization rule (weight > 0.5, 87% of the participants, see figure below). Together, these results favor the RANGE model over the DIVISIVE model in our task.
Out of curiosity, we also implemented a hybrid model as a weighted sum between absolute (UNBIASED model) and relative (RANGE model) valuations:
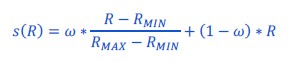
Model fitting, simulations and comparisons slightly favored this hybrid model over the UNBIASED model (oosLLHYB vs oosLLUNB: t(149)=2.63, p=.0094, d=0.15), but also drastically favored the range normalization account (oosLLHYB vs oosLLRAN : t(149)=-3.80, p=.00021, d=-0.40, see Author Response Image 2).
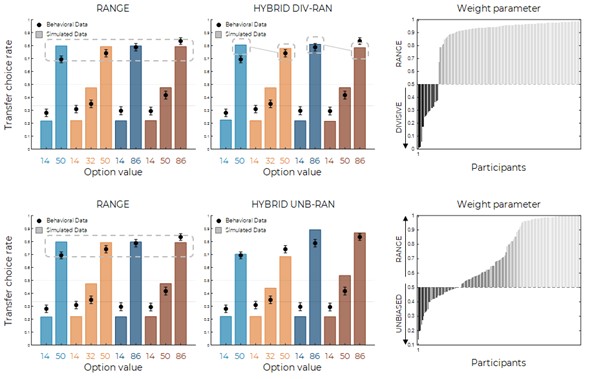
Author Response Image 2. Model simulations in the transfer phase for the RANGE model (left) and the HYBRID model (middle) defined as a weighted sum between divisive and range forms of normalization (top) and between unbiased (no normalization) and range normalization (bottom). The HYBRID model features an additional weight parameter, whose distribution favors the range normalization rule (right).
To keep things concise, we did not include this last figure in the revised manuscript, but it will be available for the interested readers in the Rebuttal letter.
Reviewer #2 (Public Review):
This paper studies how relative values are encoded in a learning task, and how they are subsequently used to make a decision. This is a topic that integrates multiple disciplines (psych, neuro, economics) and has generated significant interest. The experimental setting is based on previous work from this research team that has advanced the field's understanding of value coding in learning tasks. These experiments are well-designed to distinguish some predictions of different accounts for value encoding. However there is an additional treatment that would provide an additional (strong) test of these theories: RN would make an equivalent set of predictions if the range were equivalently adjusted downward instead (for example by adding a "68" option to "50" and "86", and then comparing to WB and WT). The predictions of DN would differ however because adding a low-value alternative to the normalization would not change it much. Would the behaviour of subjects be symmetric for equivalent ranges, as RN predicts? If so this would be a compelling result, because symmetry is a very strong theoretical assumption in this setting.
We thank the Reviewer for the overall positive appraisal concerning our work, but also for the stimulating and constructive remarks that we have addressed below. At this stage, we just wanted to mention that we also agree with the Reviewer concerning the fact that a design where we add "68" option to "50" and "86" would represent also an important test of our hypotheses. This is why we had, in fact, run this experiment. Unfortunately, their results were somehow buried in the Supplementary Materials of our original submission and not correctly highlighted in the main text. We modified the manuscript in order to make them more visible:
Behavioral results in three experiments (N=50 each) featuring a slightly different design, where we added a mid value option (NT68) between NT50 and NT87 converge to the same broad conclusion: the behavioral pattern in the transfer phase is largely incompatible with that predicted by outcome divisive normalization during the learning phase (Figure 2-figure supplement 2).
Reviewer #3 (Public Review):
Bavard & Palminteri extend their research program by devising a task that enables them to disassociate two types of normalisation: range normalisation (by which outcomes are normalised by the min and max of the options) and divisive normalisation (in which outcomes are normalised by the average of the options in ones context). By providing 4 different training contexts in which the range of outcomes and number of options vary, they successfully show using 'ex ante' simulations that different learning approaches during training (unbiased, divisive, range) should lead to different patterns of choice in a subsequent probe phase during which all options from the training are paired with one another generating novel choice pairings. These patterns are somewhat subtle but are elegantly unpacked. They then fit participants' training choices to different learning models and test how well these models predict probe phase choices. They find evidence - both in terms of quantitive (i.e. comparing out-of-sample log-likelihood scores) and qualitative (comparing the pattern of choices observed to the pattern that would be observed under each mode) fit - for the range model. This fit is further improved by adding a power parameter which suggests that alongside being relativised via range normalisation, outcomes were also transformed non-linearly.
I thought this approach to address their research question was really successful and the methods and results were strong, credible, and robust (owing to the number of experiments conducted, the design used and combination of approaches used). I do not think the paper has any major weaknesses. The paper is very clear and well-written which aids interpretability.
This is an important topic for understanding, predicting, and improving behaviour in a range of domains potentially. The findings will be of interest to researchers in interdisciplinary fields such as neuroeconomics and behavioural economics as well as reinforcement learning and cognitive psychology.
We thank Prof. Garrett for his positive evaluation and supportive attitude.
-
eLife assessment
It is well established that valuation and value-based decision making is context-dependent, but the exact form of normalization has remained an open question. This study provides compelling evidence that values during reward learning are normalized based on the range of available values. These findings will be important for researchers interested in reward learning and decision-making.
-
Reviewer #1 (Public Review):
It is well established that valuation and value-based decision making is context-dependent. This manuscript presents the results of six behavioral experiments specifically designed to disentangle two prominent functional forms of value normalization during reward learning: divisive normalization and range normalization. The behavioral and modeling results are clear and convincing, showing that key features of choice behavior in the current setting are incompatible with divisive normalization but are well predicted by a non-linear transformation of range-normalized values.
Overall, this is an excellent study with important implications for reinforcement learning and decision-making research. The manuscript could be strengthened by examining individual variability in value normalization, as outlined below.
Ther…
Reviewer #1 (Public Review):
It is well established that valuation and value-based decision making is context-dependent. This manuscript presents the results of six behavioral experiments specifically designed to disentangle two prominent functional forms of value normalization during reward learning: divisive normalization and range normalization. The behavioral and modeling results are clear and convincing, showing that key features of choice behavior in the current setting are incompatible with divisive normalization but are well predicted by a non-linear transformation of range-normalized values.
Overall, this is an excellent study with important implications for reinforcement learning and decision-making research. The manuscript could be strengthened by examining individual variability in value normalization, as outlined below.
There is a lot of individual variation in the choice data that may potentially be explained by individual differences in normalization strategies. It would be important to examine whether there are any subgroups of subjects whose behavior is better explained by a divisive vs. range normalization process. Alternatively, it may be possible to compute an index that captures how much a given subject displays behavior compatible with divisive vs. range normalization. Seeing the distribution of such an index could provide insights into individual differences in normalization strategies.
One possibility currently not considered by the authors is that both forms of value normalization are at work at the same time. It would be interesting to see the results from a hybrid model.
-
Reviewer #2 (Public Review):
This paper studies how relative values are encoded in a learning task, and how they are subsequently used to make a decision. This is a topic that integrates multiple disciplines (psych, neuro, economics) and has generated significant interest. The experimental setting is based on previous work from this research team that has advanced the field's understanding of value coding in learning tasks. These experiments are well-designed to distinguish some predictions of different accounts for value encoding. However there is an additional treatment that would provide an additional (strong) test of these theories: RN would make an equivalent set of predictions if the range were equivalently adjusted downward instead (for example by adding a "68" option to "50" and "86", and then comparing to WB and WT). The …
Reviewer #2 (Public Review):
This paper studies how relative values are encoded in a learning task, and how they are subsequently used to make a decision. This is a topic that integrates multiple disciplines (psych, neuro, economics) and has generated significant interest. The experimental setting is based on previous work from this research team that has advanced the field's understanding of value coding in learning tasks. These experiments are well-designed to distinguish some predictions of different accounts for value encoding. However there is an additional treatment that would provide an additional (strong) test of these theories: RN would make an equivalent set of predictions if the range were equivalently adjusted downward instead (for example by adding a "68" option to "50" and "86", and then comparing to WB and WT). The predictions of DN would differ however because adding a low-value alternative to the normalization would not change it much. Would the behaviour of subjects be symmetric for equivalent ranges, as RN predicts? If so this would be a compelling result, because symmetry is a very strong theoretical assumption in this setting.
-
Reviewer #3 (Public Review):
Bavard & Palminteri extend their research program by devising a task that enables them to disassociate two types of normalisation: range normalisation (by which outcomes are normalised by the min and max of the options) and divisive normalisation (in which outcomes are normalised by the average of the options in ones context). By providing 4 different training contexts in which the range of outcomes and number of options vary, they successfully show using 'ex ante' simulations that different learning approaches during training (unbiased, divisive, range) should lead to different patterns of choice in a subsequent probe phase during which all options from the training are paired with one another generating novel choice pairings. These patterns are somewhat subtle but are elegantly unpacked. They then fit …
Reviewer #3 (Public Review):
Bavard & Palminteri extend their research program by devising a task that enables them to disassociate two types of normalisation: range normalisation (by which outcomes are normalised by the min and max of the options) and divisive normalisation (in which outcomes are normalised by the average of the options in ones context). By providing 4 different training contexts in which the range of outcomes and number of options vary, they successfully show using 'ex ante' simulations that different learning approaches during training (unbiased, divisive, range) should lead to different patterns of choice in a subsequent probe phase during which all options from the training are paired with one another generating novel choice pairings. These patterns are somewhat subtle but are elegantly unpacked. They then fit participants' training choices to different learning models and test how well these models predict probe phase choices. They find evidence - both in terms of quantitive (i.e. comparing out-of-sample log-likelihood scores) and qualitative (comparing the pattern of choices observed to the pattern that would be observed under each mode) fit - for the range model. This fit is further improved by adding a power parameter which suggests that alongside being relativised via range normalisation, outcomes were also transformed non-linearly.
I thought this approach to address their research question was really successful and the methods and results were strong, credible, and robust (owing to the number of experiments conducted, the design used and combination of approaches used). I do not think the paper has any major weaknesses. The paper is very clear and well-written which aids interpretability.
This is an important topic for understanding, predicting, and improving behaviour in a range of domains potentially. The findings will be of interest to researchers in interdisciplinary fields such as neuroeconomics and behavioural economics as well as reinforcement learning and cognitive psychology.
-
