Vocalization categorization behavior explained by a feature-based auditory categorization model
Curation statements for this article:-
Curated by eLife

Evaluation Summary:
This study combines behavioral data from guinea pigs and data from a classifier model to ask what auditory features are important for classifying vocalisations. This study is likely to be of interest to both computational and experimental neuroscientists, in particular auditory neurophysiologists and cognitive and comparative neuroscientists. A strength of this work is that a model trained on natural calls was able to predict some aspects of responses to temporally and spectrally altered cues. However, additional data, analysis, or modelling would be required to support some of the stronger claims.
(This preprint has been reviewed by eLife. We include the public reviews from the reviewers here; the authors also receive private feedback with suggested changes to the manuscript. Reviewer #1 and Reviewer #3 agreed to share their names with the authors.)
This article has been Reviewed by the following groups
Discuss this preprint
Start a discussion What are Sciety discussions?Listed in
- Evaluated articles (eLife)
Abstract
Vocal animals produce multiple categories of calls with high between- and within-subject variability, over which listeners must generalize to accomplish call categorization. The behavioral strategies and neural mechanisms that support this ability to generalize are largely unexplored. We previously proposed a theoretical model that accomplished call categorization by detecting features of intermediate complexity that best contrasted each call category from all other categories. We further demonstrated that some neural responses in the primary auditory cortex were consistent with such a model. Here, we asked whether a feature-based model could predict call categorization behavior. We trained both the model and guinea pigs (GPs) on call categorization tasks using natural calls. We then tested categorization by the model and GPs using temporally and spectrally altered calls. Both the model and GPs were surprisingly resilient to temporal manipulations, but sensitive to moderate frequency shifts. Critically, the model predicted about 50% of the variance in GP behavior. By adopting different model training strategies and examining features that contributed to solving specific tasks, we could gain insight into possible strategies used by animals to categorize calls. Our results validate a model that uses the detection of intermediate-complexity contrastive features to accomplish call categorization.
Article activity feed
-

-

Author Response
Reviewer #1 (Public Review):
This paper shows that a principled, interpretable model of auditory stimulus classification can not only capture behavioural data on which the model was trained but somewhat accurately predict behaviour for manipulated stimuli. This is a real achievement and gives an opportunity to use the model to probe potential underlying mechanisms. There are two main weaknesses. Firstly, the task is very simple: distinguishing between just two classes of stimuli. Both model and animals may be using shortcuts to solve the task, for example (this is suggested somewhat by Figure 8 which shows the guinea pig and model can both handle time-reversed stimuli).
The task structure is indeed simple. In the context of categorization tasks that are typically used in animal experiments, however, we would argue …
Author Response
Reviewer #1 (Public Review):
This paper shows that a principled, interpretable model of auditory stimulus classification can not only capture behavioural data on which the model was trained but somewhat accurately predict behaviour for manipulated stimuli. This is a real achievement and gives an opportunity to use the model to probe potential underlying mechanisms. There are two main weaknesses. Firstly, the task is very simple: distinguishing between just two classes of stimuli. Both model and animals may be using shortcuts to solve the task, for example (this is suggested somewhat by Figure 8 which shows the guinea pig and model can both handle time-reversed stimuli).
The task structure is indeed simple. In the context of categorization tasks that are typically used in animal experiments, however, we would argue that we are the higher end of stimulus complexity. Auditory categories used in most animal experiments typically employ a category boundary along a single stimulus parameter (for example, tone frequency or modulation frequency of AM noise). Only a few recent studies (for example, Yin et al., 2020; Town et al., 2018) have explored animal behavior with “non-compact” stimulus categories. Thus, we consider our task a significant step towards more naturalistic tasks.
We were also faced with the practical factor of the trainability of guinea pigs (GPs). Prior to this study, guinea pigs have been trained using classical conditioning and aversive reinforcement on detecting tone frequency (e.g., Heffner et al., 1971; Edeline et al., 1993). More recently, competitive training paradigms have been developed for appetitive conditioning, using a single “footstep” sound as a target stimulus and manipulated sounds as non-target stimuli (Ojima and Horikawa, 2016). But as GPs had never been trained on more complex tasks before our study, we started with a conservative one vs. one categorization task. We mention this in the Discussion section of the revised manuscript (page 27, line 665).
To determine whether these results hold for more complex tasks as well, after receiving the reviews of the original manuscript, we trained two GPs (that were originally trained and tested on the wheeks vs. whines task) further on a wheeks vs. many (whines, purrs, chuts) task. As earlier, we tested these GPs with new exemplars and verified that they generalized. In the figure below, the average performance of the two GPs on the regular (training) stimuli and novel (generalization) stimuli are shown in gray bars, and individual animal performances are shown as colored discs. The GPs achieved high performance for the novel stimuli, demonstrating generalization. We also implemented a 4-way WTA stage for a wheek vs. many model and verified that the model generalized to new stimuli as well.
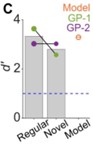
For frequency-shifted calls, these two GPs performed better for wheeks vs. many compared to the average for wheeks vs. whines shown in the main manuscript. The 4-way WTA model closely tracked GP behavioral trends.
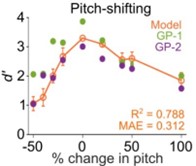
The psychometric curves for wheeks vs. many categorization in noise (different SNRs) did not differ substantially from the wheeks vs. whines task.
We focused our one vs. many training on the two conditions that showed the greatest modulation in the one vs. one tasks. However, these preliminary results suggest that the one vs. one results presented in the manuscript are likely to extend to more complex classification tasks as well. We chose not to include these new data in the revised manuscript because we performed these experiments on only 2 animals, which were previously trained on a wheeks vs. whines task. In future studies, we plan to directly train animals on one vs. many tasks.
Secondly, the predictions of the model do not appear to be quite as strong as the abstract and text suggest.
We now replace subjective descriptors with actual effect size numbers to avoid overstatingresults. We also include additional modeling (classification based on the long-term spectrum) and discuss alternative possibilities to provide readers with points of comparison. Thus, readers can form their own opinions of the strengths of the observed effects.
The model uses "maximally informative features" found by randomly initialising 1500 possible features and selecting the 20 most informative (in an information-theoretic sense). This is a really interesting approach to take compared to directly optimising some function to maximise performance at a task, or training a deep neural network. It is suggestive of a plausible biological approach and may serve to avoid overfitting the data. In a machine learning sense, it may be acting as a sort of regulariser to avoid overfitting and improve generalisation. The 'features' used are basically spectro-temporal patterns that are matched by sliding a crosscorrelator over the signal and thresholding, which is straightforward and interpretable.
This intuition is indeed accurate – the greedy search algorithm (described in the original visionpaper by Ullman et al., 2002) sequentially adds features that add the most hits and the least false alarms compared to existing members of the MIF set to the final MIF set. The latter criterion (least false alarms) essentially guards against over-fitting for hits alone. A second factor is the intermediate size and complexity of MIFs. When MIFs are too large, there is certainly overfitting to the training exemplars, and the model does not generalize well (Liu et al., 2019).
It is surprising and impressive that the model is able to classify the manipulated stimuli at all. However, I would slightly take issue with the statement that they match behaviour "to a remarkable degree". R^2 values between model and behaviour are 0.444, 0.674, 0.028, 0.011, 0.723, 0.468. For example, in figure 5 the lower R^2 value comes out because the model is not able to use as short segments as the guinea pigs (which the authors comment on in the results and discussion). In figure 6A (speeding up and slowing down the stimuli), the model does worse than the guinea pigs for faster stimuli and better for slower stimuli, which doesn't qualitatively match (not commented on by the authors). The authors state that the poor match is "likely because of random fluctuations in behavior (e..g motivation) across conditions that are unrelated to stimulus parameters" but it's not clear why that would be the case for this experiment and not for others, and there is no evidence shown for it.
Thank you for this feedback. There are two levels at which we addressed these comments inthe revised manuscript.
First, regarding the language – we have now replaced subjective descriptors with the statement that the model captures ~50% of the overall variance in behavioral data. The ~50% number is the average overall R2 between the model and data (0.6 and 0.37 for the chuts vs. purrs and wheeks vs. whine tasks respectively). We leave it to readers to interpret this number.
Second, our original manuscript lacked clarity on exactly what aspects of the categorization behavior we were attempting to model. As recent studies have suggested, categorization behavior can be decomposed into two steps – the acquisition of the knowledge of auditory categories, and the expression of this knowledge in an operant task (Kuchibhotla et al., 2019; Moore and Kuchibhotla, 2022). Our model solely addresses how knowledge regarding categories is acquired (through the detection of maximally informative features). Other than setting a 10% error in our winner-take-all stage, we did not attempt to systematically model any other cognitive-behavioral effects such as the effect of motivation and arousal. Thus, in the revised manuscript, we have included a paragraph at the top of the Results section that defines our intent more clearly (page 5, line 117). We conclude the initial description of the behavior by stating that these factors are not intended to be captured by the model (page 6, line 171). We also edited a paragraph in the Discussion section for clarity on this point (page 26, line 629).
In figure 11, the authors compare the results of training their model with all classes, versus training only with the classes used in the task, and show that with the latter performance is worse and matches the experiment less well. This is a very interesting point, but it could just be the case that there is insufficient training data.
This could indeed be the case, and we acknowledge this as a potential explanation in therevised manuscript (page 22, line 537; page 27, line 653). Our original thinking was that if GPs were also learning discriminative features only using our training exemplars, they would face a similar training data constraint as well. But despite this constraint, the model’s performance is above d’=1 for natural calls – both training and novel calls; it is only the similarity with behavior on the manipulated stimuli that is lower than the one vs. many model. This phenomenon warrants further investigation.
Reviewer #2 (Public Review):
Kar et al aim to further elucidate the main features representing call type categorization in guinea pigs. This paper presents a behavioral paradigm in which 8 guinea pigs (GPs) were trained in a call categorization task between pairs of call types (chuts vs purrs; wheek vs whines). The GPs successfully learned the task and are able to generalize to new exemplars. GPs were tested across pitch-shifted stimuli and stimuli with various temporal manipulations. Complementing this data is multivariate classifier data from a model trained to perform the same task. The classifier model is trained on auditory nerve outputs (not behavioral data) and reaches an accuracy metric comparable to that of the GPs. The authors argue that the model performance is similar to that of the GPs in the manipulated stimuli, therefore, suggesting that the 'mid-level features' that the model uses may be similar to those exploited by the GPs. The behavioral data is impressive: to my knowledge, there is scant previous behavioral data from GPs performing an auditory task beyond audiograms measured using aversive conditioning by Heffner et al., in. 1970. [One exception that is notably omitted from the manuscript is Ojima and Horikawa 2016 (Frontiers)]. Given the popularity of GPs as a model of auditory neurophysiology these data open new avenues for investigation. This paper would be useful for neuroscientists using classifier models to simulate behavioral choice data in similar Go/No-Go experiments, especially in guinea pigs. The significance of the findings rests on the similarity (or not) of the model and GP performance as a validation of the 'intermediary features' approach for categorization. At the moment the study is underpowered for the statistical analysis the authors attempt to employ which frequently relies on non-significant p values for its conclusions; using a more sophisticated approach (a mixed effects model utilizing single trial responses) would provide a more rigorous test of the manipulations on behavior and allow a more complete assessment of the authors' conclusions.
We thank the reviewer for their feedback and the suggestion for a more robust statistical approach. We have now replaced the repeated measures ANOVA based statistics for the behavior and model where more than 2 test conditions were presented (SNR, segment length, tempo shift, and frequency shift) with generalized linear models with a logit link function (logistic activation function). In these models, we predict the trial-by-trial behavioral or model outcome from predictors including stimulus type (Go or Nogo), parameter value (e.g., SNR value), parameter sign (e.g., positive or negative freq. shift), and animal ID as a random effect. To evaluate whether parameter value and sign had a significant contribution to the model, we compare this ‘full’ model against a null model that only has stimulus type as a predictor and animal ID as a random effect. These analyses are described in detail in the Materials and Methods section of the revised manuscript (page 36, line 930).
These analyses reveal significant effects of segment length changes, and weak effects of tempo changes on behavior (as expected by the reviewer). Both the behavior and model showed similar statistical significance (except tempo shift for wheeks vs. whines) for whether performance was significantly affected by a given parameter.
The behavioral data presented here are descriptive. The central conceptual conclusions of the manuscript are derived from the comparison between the model and behavioral data. For these comparisons, the p-value of statistical tests is not used. We realized that a description of how we compared model and behavioral data was not clear in the original manuscript. To compare behavioral data with the model, we fit a line to the d’ values obtained from the model plotted against the d’ values obtained from behavior, and computed the R2 value. We used the mean absolute error (MAE) to quantify the absolute deviation between model and behavior d’ values. Thus, high R2 values would signify a close correspondence between the model and behavior regardless of statistical significance of individual data points. We now clarify this in page 12, line 289. We derive R2 values for individual stimulus manipulations, as well as an overall R2 by pooling across all manipulations (presented in Fig. 11). This is now clarified in page 21, line 494.
Reviewer #3 (Public Review):
The authors designed a behavioral experiment based on a Go/ No-Go paradigm, to train guinea pigs on call categorization. They used two different pairs of call categories: chuts vs. purrs and wheeks vs. whines. During the training of the animals, it turned out that they change their behavioral strategies. Initially, they do not associate the auditory stimuli with rewards, and hence they overweight the No-Go behavior (low hit and false alarm rate). Subsequently, they learned the association between auditory stimuli and reward, leading to overweighting the Go behavior (high hit and false alarm rates). Finally, they learn to discriminate between the two call categories and show the corresponding behaviors, i.e. suppress the Go behavior for No-go stimuli (improved discrimination performance due to stable hit rates but lower false alarm rates).
In order to derive a mechanistic explanation of the observed behaviors, the authors implemented a computational feature-based model, with which they mirrored all animal experiments, and subsequently compared the resulting performances.
Strengths:
In order to construct their model, the authors identified several different sets of so-called MIFs (most informative features) for each call category, that were best suited to accomplish the categorization task. Overall, model performance was in general agreement with behavioral performance for both the chuts vs. purrs and wheeks vs. whines tasks, in a wide range of different scenarios.
Different instances of their model, i.e. models using different of those sets of MIFs, performed equally well. In addition, the authors could show that guinea pigs and models can generalize to categorize new call exemplars very rapidly.
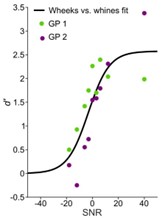
The authors also tested the categorization performance of guinea pigs and models in a more realistic scenario, i.e. communication in noisy environments. They find that both, guinea pigs and the model exhibit similar categorization-in-noise thresholds.
Additionally, the authors also investigated the effect of temporal stretching/compression of calls on categorization performance. Remarkably, this had virtually no negative effect on both, models and animals. And both performed equally well, even for time reversal. Finally, the authors tested the effect of pitch change on categorization performance, and found very similar effects in guinea pigs and models: discrimination performance crucially depends on pitch change, i.e. systematically decreases with the percentage of change.
Weaknesses:
While their computational model can explain certain aspects of call categorization after training, it cannot explain the time course of different behavioral strategies shown by the guinea pigs during learning/training.
Thank you for bringing this up – in hindsight the original manuscript lacked clarity on exactlywhat aspects of the behavior we were trying to model. As recent studies have suggested, categorization behavior can be decomposed into two steps – the acquisition of the knowledge of auditory categories, and the expression of this knowledge in an operant task (Kuchibhotla et al., 2019; Moore and Kuchibhotla, 2022) . Our model solely addresses how knowledge regarding categories is acquired (through the detection of maximally informative features). Other than setting a 10% error in our winner-take-all stage, we did not attempt to systematically model any other cognitive-behavioral effects such as the effect of motivation and arousal, or behavioral strategies. Thus, in the revised manuscript, we have included a paragraph at the top of the Results section that defines our intent more clearly (page 5, line 117). We conclude the initial description of the behavior by stating that these factors are not intended to be captured by the model (page 6, line 171). We also edited a paragraph in the Discussion section for clarity on this point (page 26, line 629).
Furthermore, the model cannot account for the fact that short-duration segments of calls (50ms) already carry sufficient information for call categorization in the guinea pig experiment. Model performance, however, only plateaued after a 200 ms duration, which might be due to the fact that the MIFs were on average about 110 ms long.
The segment-length data indeed demonstrates a deviation between the data and the model.As we had acknowledged in the original manuscript, this observation suggests further constraints (perhaps on feature length and/or bandwidth) that need to be imposed on the model to better match GP behavior. We originally did not perform this analysis because we wanted to demonstrate that a model with minimal assumptions and parameter tuning could capture aspects of GP behavior.
We have now repeated the modeling by constraining the features to a duration of 75 ms (thelowest duration for which GPs show above-threshold performance). We found that the constrained MIF model better matched GP behavior on the segment-length task (R2 of 0.62 and 0.58 for the chuts vs. purrs and wheeks vs. whines tasks; with the model crossing d’=1 for 75 ms segments for most tested cases). The constrained MIF model maintained similarity to behavior for the other manipulations as well, and yielded higher overall R2 values (0.66 for chuts vs. purrs, 0.51 for wheeks vs. whines), thereby explaining an additional 10% of variance in GP behavior.
In the revised manuscript, we included these results (page 28, line 699), and present results from the new analyses as Figure 11 – Figure Supplement 2.
In the temporal stretching/compressing experiment, it remains unclear, if the corresponding MIF kernels used by the models were just stretched/compressed in a temporal direction to compensate for the changed auditory input. If so, the modelling results are trivial. Furthermore, in this case, the model provides no mechanistic explanation of the underlying neural processes. Similarly, in the pitch change experiment, if MIF kernels have been stretched/compressed in the pitch direction, the same drawback applies.
We did not alter the MIFs in any way for the tests – the MIFs were purely derived by trainingthe animal on natural calls. In learning to generalize over the variability in natural calls, the model also achieved the ability to generalize over some manipulated stimuli. The fact that the model tracks GP behavior is a key observation supporting our argument that GPs also learn MIF-like features to accomplish call categorization.
We had mentioned at a few places that the model was only trained on natural calls. To addclarity, we have now included sentences in the time-compression and frequency-shifting results affirming that we did not manipulate the MIFs to match test stimuli. We also include a couple of sentences in the Discussion section’s first paragraph stating the above argument (page 26, line 615).
-
Evaluation Summary:
This study combines behavioral data from guinea pigs and data from a classifier model to ask what auditory features are important for classifying vocalisations. This study is likely to be of interest to both computational and experimental neuroscientists, in particular auditory neurophysiologists and cognitive and comparative neuroscientists. A strength of this work is that a model trained on natural calls was able to predict some aspects of responses to temporally and spectrally altered cues. However, additional data, analysis, or modelling would be required to support some of the stronger claims.
(This preprint has been reviewed by eLife. We include the public reviews from the reviewers here; the authors also receive private feedback with suggested changes to the manuscript. Reviewer #1 and Reviewer #3 agreed to …
Evaluation Summary:
This study combines behavioral data from guinea pigs and data from a classifier model to ask what auditory features are important for classifying vocalisations. This study is likely to be of interest to both computational and experimental neuroscientists, in particular auditory neurophysiologists and cognitive and comparative neuroscientists. A strength of this work is that a model trained on natural calls was able to predict some aspects of responses to temporally and spectrally altered cues. However, additional data, analysis, or modelling would be required to support some of the stronger claims.
(This preprint has been reviewed by eLife. We include the public reviews from the reviewers here; the authors also receive private feedback with suggested changes to the manuscript. Reviewer #1 and Reviewer #3 agreed to share their names with the authors.)
-
Reviewer #1 (Public Review):
This paper shows that a principled, interpretable model of auditory stimulus classification can not only capture behavioural data on which the model was trained but somewhat accurately predict behaviour for manipulated stimuli. This is a real achievement and gives an opportunity to use the model to probe potential underlying mechanisms. There are two main weaknesses. Firstly, the task is very simple: distinguishing between just two classes of stimuli. Both model and animals may be using shortcuts to solve the task, for example (this is suggested somewhat by Figure 8 which shows the guinea pig and model can both handle time-reversed stimuli). Secondly, the predictions of the model do not appear to be quite as strong as the abstract and text suggest.
The model uses "maximally informative features" found by …
Reviewer #1 (Public Review):
This paper shows that a principled, interpretable model of auditory stimulus classification can not only capture behavioural data on which the model was trained but somewhat accurately predict behaviour for manipulated stimuli. This is a real achievement and gives an opportunity to use the model to probe potential underlying mechanisms. There are two main weaknesses. Firstly, the task is very simple: distinguishing between just two classes of stimuli. Both model and animals may be using shortcuts to solve the task, for example (this is suggested somewhat by Figure 8 which shows the guinea pig and model can both handle time-reversed stimuli). Secondly, the predictions of the model do not appear to be quite as strong as the abstract and text suggest.
The model uses "maximally informative features" found by randomly initialising 1500 possible features and selecting the 20 most informative (in an information-theoretic sense). This is a really interesting approach to take compared to directly optimising some function to maximise performance at a task, or training a deep neural network. It is suggestive of a plausible biological approach and may serve to avoid overfitting the data. In a machine learning sense, it may be acting as a sort of regulariser to avoid overfitting and improve generalisation. The 'features' used are basically spectro-temporal patterns that are matched by sliding a cross-correlator over the signal and thresholding, which is straightforward and interpretable.
It is surprising and impressive that the model is able to classify the manipulated stimuli at all. However, I would slightly take issue with the statement that they match behaviour "to a remarkable degree". R^2 values between model and behaviour are 0.444, 0.674, 0.028, 0.011, 0.723, 0.468. For example, in figure 5 the lower R^2 value comes out because the model is not able to use as short segments as the guinea pigs (which the authors comment on in the results and discussion). In figure 6A (speeding up and slowing down the stimuli), the model does worse than the guinea pigs for faster stimuli and better for slower stimuli, which doesn't qualitatively match (not commented on by the authors). The authors state that the poor match is "likely because of random fluctuations in behavior (e..g motivation) across conditions that are unrelated to stimulus parameters" but it's not clear why that would be the case for this experiment and not for others, and there is no evidence shown for it.
In figure 11, the authors compare the results of training their model with all classes, versus training only with the classes used in the task, and show that with the latter performance is worse and matches the experiment less well. This is a very interesting point, but it could just be the case that there is insufficient training data.
-
Reviewer #2 (Public Review):
Kar et al aim to further elucidate the main features representing call type categorization in guinea pigs. This paper presents a behavioral paradigm in which 8 guinea pigs (GPs) were trained in a call categorization task between pairs of call types (chuts vs purrs; wheek vs whines). The GPs successfully learned the task and are able to generalize to new exemplars. GPs were tested across pitch-shifted stimuli and stimuli with various temporal manipulations. Complementing this data is multivariate classifier data from a model trained to perform the same task. The classifier model is trained on auditory nerve outputs (not behavioral data) and reaches an accuracy metric comparable to that of the GPs. The authors argue that the model performance is similar to that of the GPs in the manipulated stimuli, therefore, …
Reviewer #2 (Public Review):
Kar et al aim to further elucidate the main features representing call type categorization in guinea pigs. This paper presents a behavioral paradigm in which 8 guinea pigs (GPs) were trained in a call categorization task between pairs of call types (chuts vs purrs; wheek vs whines). The GPs successfully learned the task and are able to generalize to new exemplars. GPs were tested across pitch-shifted stimuli and stimuli with various temporal manipulations. Complementing this data is multivariate classifier data from a model trained to perform the same task. The classifier model is trained on auditory nerve outputs (not behavioral data) and reaches an accuracy metric comparable to that of the GPs. The authors argue that the model performance is similar to that of the GPs in the manipulated stimuli, therefore, suggesting that the 'mid-level features' that the model uses may be similar to those exploited by the GPs. The behavioral data is impressive: to my knowledge, there is scant previous behavioral data from GPs performing an auditory task beyond audiograms measured using aversive conditioning by Heffner et al., in. 1970. [One exception that is notably omitted from the manuscript is Ojima and Horikawa 2016 (Frontiers)]. Given the popularity of GPs as a model of auditory neurophysiology these data open new avenues for investigation. This paper would be useful for neuroscientists using classifier models to simulate behavioral choice data in similar Go/No-Go experiments, especially in guinea pigs. The significance of the findings rests on the similarity (or not) of the model and GP performance as a validation of the 'intermediary features' approach for categorization. At the moment the study is underpowered for the statistical analysis the authors attempt to employ which frequently relies on non-significant p values for its conclusions; using a more sophisticated approach (a mixed effects model utilizing single trial responses) would provide a more rigorous test of the manipulations on behavior and allow a more complete assessment of the authors' conclusions.
-
Reviewer #3 (Public Review):
The authors designed a behavioral experiment based on a Go/ No-Go paradigm, to train guinea pigs on call categorization. They used two different pairs of call categories: chuts vs. purrs and wheeks vs. whines. During the training of the animals, it turned out that they change their behavioral strategies. Initially, they do not associate the auditory stimuli with rewards, and hence they overweight the No-Go behavior (low hit and false alarm rate). Subsequently, they learned the association between auditory stimuli and reward, leading to overweighting the Go behavior (high hit and false alarm rates). Finally, they learn to discriminate between the two call categories and show the corresponding behaviors, i.e. suppress the Go behavior for No-go stimuli (improved discrimination performance due to stable hit …
Reviewer #3 (Public Review):
The authors designed a behavioral experiment based on a Go/ No-Go paradigm, to train guinea pigs on call categorization. They used two different pairs of call categories: chuts vs. purrs and wheeks vs. whines. During the training of the animals, it turned out that they change their behavioral strategies. Initially, they do not associate the auditory stimuli with rewards, and hence they overweight the No-Go behavior (low hit and false alarm rate). Subsequently, they learned the association between auditory stimuli and reward, leading to overweighting the Go behavior (high hit and false alarm rates). Finally, they learn to discriminate between the two call categories and show the corresponding behaviors, i.e. suppress the Go behavior for No-go stimuli (improved discrimination performance due to stable hit rates but lower false alarm rates).
In order to derive a mechanistic explanation of the observed behaviors, the authors implemented a computational feature-based model, with which they mirrored all animal experiments, and subsequently compared the resulting performances.Strengths:
In order to construct their model, the authors identified several different sets of so-called MIFs (most informative features) for each call category, that were best suited to accomplish the categorization task. Overall, model performance was in general agreement with behavioral performance for both the chuts vs. purrs and wheeks vs. whines tasks, in a wide range of different scenarios.Different instances of their model, i.e. models using different of those sets of MIFs, performed equally well. In addition, the authors could show that guinea pigs and models can generalize to categorize new call exemplars very rapidly.
The authors also tested the categorization performance of guinea pigs and models in a more realistic scenario, i.e. communication in noisy environments. They find that both, guinea pigs and the model exhibit similar categorization-in-noise thresholds.Additionally, the authors also investigated the effect of temporal stretching/compression of calls on categorization performance. Remarkably, this had virtually no negative effect on both, models and animals. And both performed equally well, even for time reversal.
Finally, the authors tested the effect of pitch change on categorization performance, and found very similar effects in guinea pigs and models: discrimination performance crucially depends on pitch change, i.e. systematically decreases with the percentage of change.Weaknesses:
While their computational model can explain certain aspects of call categorization after training, it cannot explain the time course of different behavioral strategies shown by the guinea pigs during learning/training.
Furthermore, the model cannot account for the fact that short-duration segments of calls (50ms) already carry sufficient information for call categorization in the guinea pig experiment. Model performance, however, only plateaued after a 200 ms duration, which might be due to the fact that the MIFs were on average about 110 ms long.In the temporal stretching/compressing experiment, it remains unclear, if the corresponding MIF kernels used by the models were just stretched/compressed in a temporal direction to compensate for the changed auditory input. If so, the modelling results are trivial. Furthermore, in this case, the model provides no mechanistic explanation of the underlying neural processes. Similarly, in the pitch change experiment, if MIF kernels have been stretched/compressed in the pitch direction, the same drawback applies.
Discussion:
The authors claim that intermediate-level features of auditory stimuli, like the identified MIFs, are most useful to accomplish call categorization. This is supported by several findings, e.g. that both, guinea pigs and the model exhibit similar categorization-in-noise thresholds. Furthermore, animals and models are astonishingly robust against temporal stretching/compression, and even time reversal. Finally, both show a strong effect of pitch change on discrimination performance. -
