Structural differences in adolescent brains can predict alcohol misuse
Curation statements for this article:-
Curated by eLife

Evaluation Summary:
This study uses a large dataset on alcohol misuse in adolescents that have been followed up for several years. MRI data are used to test whether the structure and connectivity of the brains of adolescents can predict their alcohol misuse later in their early twenties. The results show that binge drinking can be predicted out of multiple brain phenotypes with a good accuracy, even after control for many confound variables. This study can be impactful as it suggests a reevaluation of studies of the effect of alcohol on the adolescent brain.
(This preprint has been reviewed by eLife. We include the public reviews from the reviewers here; the authors also receive private feedback with suggested changes to the manuscript. The reviewers remained anonymous to the authors.)
This article has been Reviewed by the following groups
Discuss this preprint
Start a discussion What are Sciety discussions?Listed in
- Evaluated articles (eLife)
Abstract
Alcohol misuse during adolescence (AAM) has been associated with disruptive development of adolescent brains. In this longitudinal machine learning (ML) study, we could predict AAM significantly from brain structure (T1-weighted imaging and DTI) with accuracies of 73 -78% in the IMAGEN dataset (n∼1182). Our results not only show that structural differences in brain can predict AAM, but also suggests that such differences might precede AAM behavior in the data. We predicted 10 phenotypes of AAM at age 22 using brain MRI features at ages 14, 19, and 22. Binge drinking was found to be the most predictable phenotype. The most informative brain features were located in the ventricular CSF, and in white matter tracts of the corpus callosum, internal capsule, and brain stem. In the cortex, they were spread across the occipital, frontal, and temporal lobes and in the cingulate cortex. We also experimented with four different ML models and several confound control techniques. Support Vector Machine (SVM) with rbf kernel and Gradient Boosting consistently performed better than the linear models, linear SVM and Logistic Regression. Our study also demonstrates how the choice of the predicted phenotype, ML model, and confound correction technique are all crucial decisions in an explorative ML study analyzing psychiatric disorders with small effect sizes such as AAM.
Article activity feed
-

-

Author Responses
Reviewer #1 (Public Review):
This study uses a nice longitudinal dataset and performs relatively thorough methodological comparisons. I also appreciate the systematic literature review presented in the introduction. The discussion of confound control is interesting and it is great that a leave-one-site-out test was included. However, the prediction accuracy drops in these important leave-one-site-out analyses, which should be assessed and discussed further.
Furthermore, I think there is a missed opportunity to test longitudinal prediction using only pre-onset individuals to gain clearer causal insights. Please find specific comments below, approximately in order of importance.
We thank the reviewers for their positive remarks and for providing important suggestions to improve the analysis. Please see our detailed …
Author Responses
Reviewer #1 (Public Review):
This study uses a nice longitudinal dataset and performs relatively thorough methodological comparisons. I also appreciate the systematic literature review presented in the introduction. The discussion of confound control is interesting and it is great that a leave-one-site-out test was included. However, the prediction accuracy drops in these important leave-one-site-out analyses, which should be assessed and discussed further.
Furthermore, I think there is a missed opportunity to test longitudinal prediction using only pre-onset individuals to gain clearer causal insights. Please find specific comments below, approximately in order of importance.
We thank the reviewers for their positive remarks and for providing important suggestions to improve the analysis. Please see our detailed comments below.
- The leave-one-site-out results fail to achieve significant prediction accuracy for any of the phenotypes. This reveals a lack of cross-site generalizability of all results in this work. The authors discuss that this variance could be caused by distributed sample sizes across sites resulting in uneven folds or site-specific variance. It should be possible to test these hypotheses by looking at the relative performance across CV folds. The site-specific variance hypothesis may be likely because for the other results confounds are addressed using oversampling (i.e., sampling with replacement) which creates a large sample with lower variance than a random sample of the same size. This is an important null finding that may have important implications, so I do not think that it is cause for rejection. However, it is a key element of this paper and I think it should be assessed further and discussed more widely in the abstract and conclusion.
We thank the reviewer for raising this point and providing specific suggestions. As mentioned by the reviewer, the leave-one-site-out results showed high-variance across sites, that is, across cross validation (CV) folds. Therefore, as suggested by the reviewer, we further investigated the source of this variance by observing how the model accuracies correlates with each site and its sample sizes, ratio of AAM-to-controls, and the sex distribution in each site. We ranked the sites from low to high accuracy and observed different performance metrics such as sensitivity and specificity:
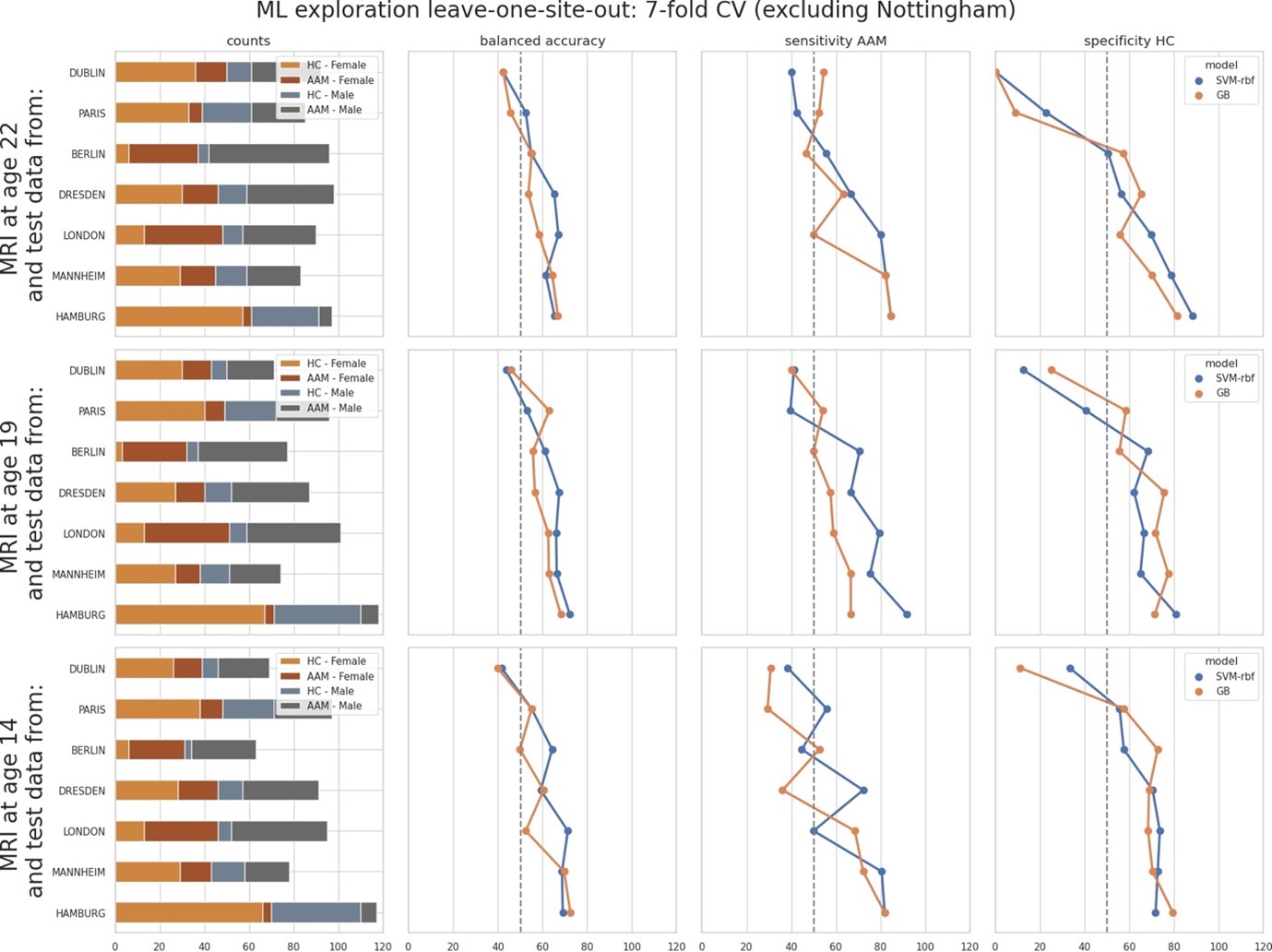
As shown, the models performed close-to-chance for sites ‘Dublin’, ‘Paris’ and ‘Berlin’ (<60% mean balanced accuracy) in the leave-one-site-out experiment, across all time-points and metrics. Notably, the order of the performance at each site does not correspond to the sample sizes (please refer to the ‘counts’ column in the above figure). It also does not correspond to the ratio of AAM-to-controls, or to the sex distribution.
To further investigate this, we performed another additional leave-one-site-out experiment with all 8 sites. Here, we repeated the ML (Machine Learning) exploration by using the entire data, including the data from the Nottingham site that was kept aside as the holdout. Since there are 8 sites now, we used a 8-fold cross validation and observed how the model accuracy varied across each site:
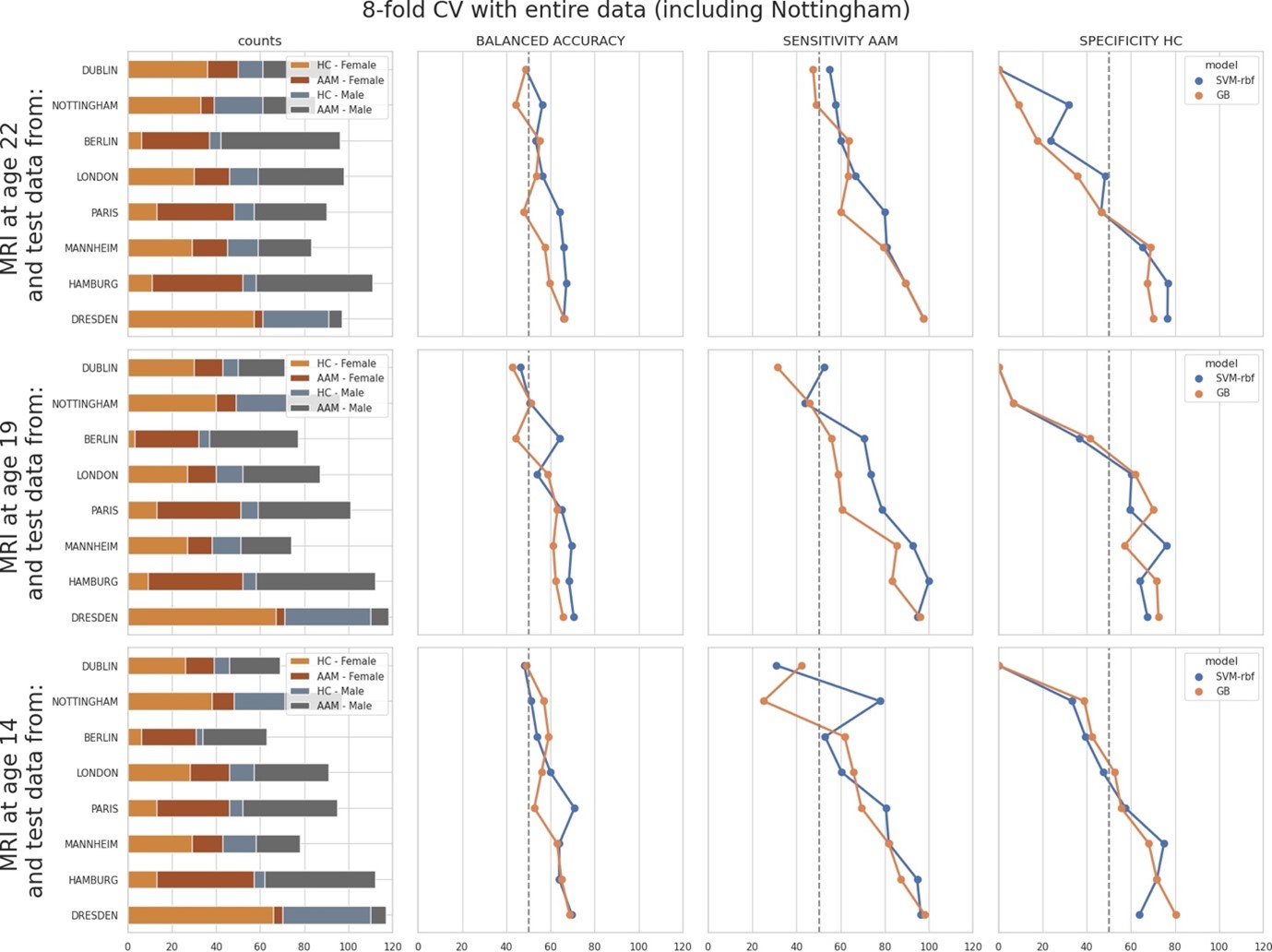
The results were comparable to the original leave-one-site-out experiment. Along with ‘Dublin’ and Berlin’, the models additionally performed poorly on the ‘Nottingham’ site. Results on ‘London’ and ‘Paris’ also fell below 60% mean balanced accuracy.
Finally, we compared the above two results to the main experiment from the paper where the test samples were randomly sampled across all sites. The performance on test subjects from each site was compared:
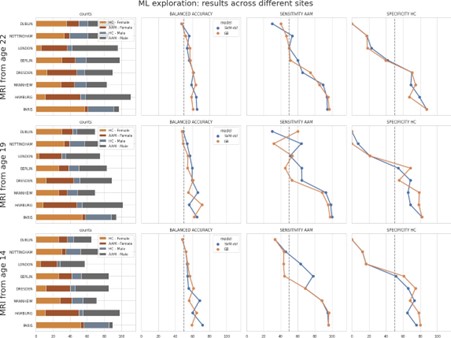
As seen, the models struggled with subjects from ‘Dublin’ followed by ‘Nottingham’ ‘London’ and ‘Berlin’ respectively, and performed well on subjects from ‘Dresden’, ‘Mannheim’, ‘Hamburg’ and ‘Paris’.
Across all the three results discussed above, the models consistently struggle to generalize to subjects particularly from ‘Dublin’ and ‘Nottingham’. As already pointed out by the reviewer, the variance in the main experiment in the manuscript is lower because of the random sampling of the test set across all sites. Since these results have important implications, we have included them in the manuscript and also provided these figures in the Appendix.
- The authors state that "83.3% of subjects reported having no or just one binge drinking experience until age 14". To gain clearer insights into the causality, I recommend repeating the MRIage14 → AAMage22 prediction using only these 83% of subjects.
We thank the reviewer for this valuable comment. As suggested by the reviewer, we now repeated the MRIage14 → AAMage22 analysis by including (a) only the subjects who had no binge drinking experiences (n=477) by age 14 and (b) subjects who had one or less binge drinking experiences (n=565). The results are shown below. The balanced accuracy on the holdout set were 72.9 +/- 2% and 71.1 +/- 2.3% respectively, which is comparable to the main result of 73.1 +/- 2%.
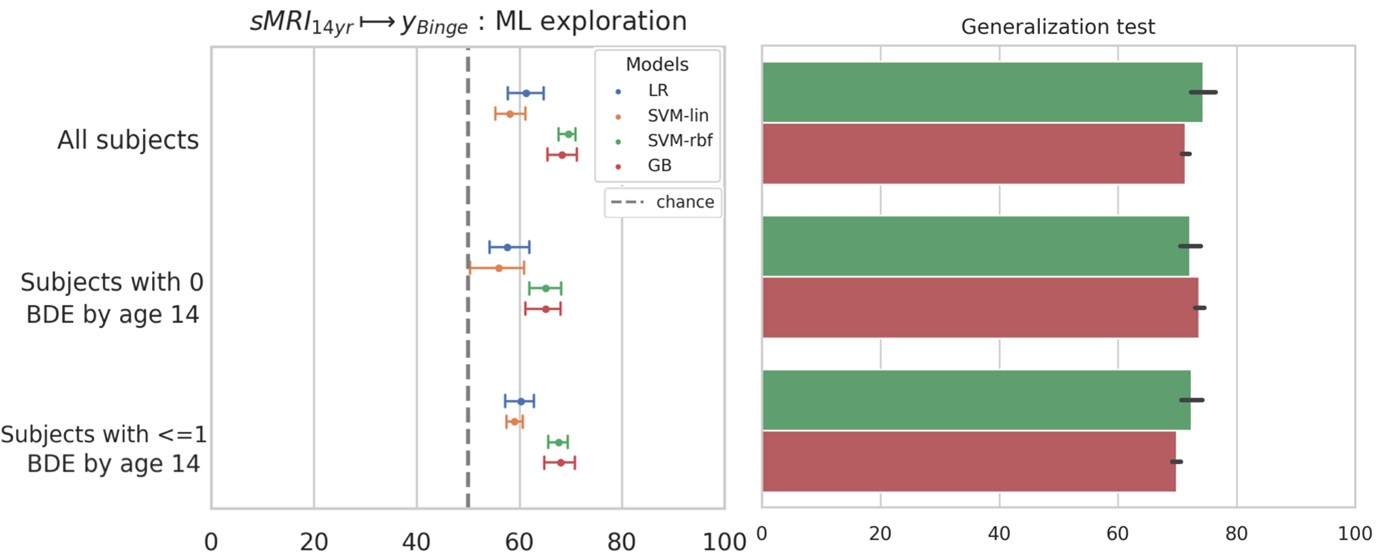
These results provide further evidence that certain form of cerebral predisposition might be preceding the observed alcohol misuse behavior in the IMAGEN dataset. We discuss these results now in the Results section and the 2nd paragraph of Discussion.
- The feature importance results for brain regions are quite inconsistent across time points. As such, the study doesn't really address one of the main challenges with previous work discussed in the introduction: "brain regions reported were not consistent between these studies either and do not tell a coherent story". This would be worth looking into further, for example by looking at other indices of feature importance such as permutation-based measures and/or investigating the stability of feature importance across bootstrapped CV folds.
The feature importance results shown in Figure 9 is intended to be illustrative and show where the most informative structural features are mainly clustered around in the brain, for each time point. We would like to acknowledge that this figure could be a bit confusing. Hence, we have now provided an exhaustive table in the Appendix, consisting of all important features and their respective SHAP scores obtained across the seven repeated runs. In addition, we address the inconsistencies across time points in the 3rd paragraph in the Discussion chapter and contrast our findings with previous studies. These claims can now be verified from the table of features provided in the Appendix.
Addressing the reviewer's suggestions, we would like to point out that SHAP is itself a type of permutation-based measure of feature importance. Since it derives from the theoretically-sound shapley values, is model agnostic, and has been already applied for biomedical applications, we believe that running another permutation-based analysis would not be beneficial. We have also investigated the stability of our feature importance scores by repeating the SHAP estimation with different random permutations. This process is explained in the Methods section Model Interpretation.
Additionally now, the SHAP scores across the seven repetitions are also provided in the Appendix table 6 for verification.
-
Evaluation Summary:
This study uses a large dataset on alcohol misuse in adolescents that have been followed up for several years. MRI data are used to test whether the structure and connectivity of the brains of adolescents can predict their alcohol misuse later in their early twenties. The results show that binge drinking can be predicted out of multiple brain phenotypes with a good accuracy, even after control for many confound variables. This study can be impactful as it suggests a reevaluation of studies of the effect of alcohol on the adolescent brain.
(This preprint has been reviewed by eLife. We include the public reviews from the reviewers here; the authors also receive private feedback with suggested changes to the manuscript. The reviewers remained anonymous to the authors.)
-
Reviewer #1 (Public Review):
This study uses a nice longitudinal dataset and performs relatively thorough methodological comparisons. I also appreciate the systematic literature review presented in the introduction. The discussion of confound control is interesting and it is great that a leave-one-site-out test was included. However, the prediction accuracy drops in these important leave-one-site-out analyses, which should be assessed and discussed further. Furthermore, I think there is a missed opportunity to test longitudinal prediction using only pre-onset individuals to gain clearer causal insights. Please find specific comments below, approximately in order of importance.
1. The leave-one-site-out results fail to achieve significant prediction accuracy for any of the phenotypes. This reveals a lack of cross-site generalizability of …
Reviewer #1 (Public Review):
This study uses a nice longitudinal dataset and performs relatively thorough methodological comparisons. I also appreciate the systematic literature review presented in the introduction. The discussion of confound control is interesting and it is great that a leave-one-site-out test was included. However, the prediction accuracy drops in these important leave-one-site-out analyses, which should be assessed and discussed further. Furthermore, I think there is a missed opportunity to test longitudinal prediction using only pre-onset individuals to gain clearer causal insights. Please find specific comments below, approximately in order of importance.
1. The leave-one-site-out results fail to achieve significant prediction accuracy for any of the phenotypes. This reveals a lack of cross-site generalizability of all results in this work. The authors discuss that this variance could be caused by distributed sample sizes across sites resulting in uneven folds or site-specific variance. It should be possible to test these hypotheses by looking at the relative performance across CV folds. The site-specific variance hypothesis may be likely because for the other results confounds are addressed using oversampling (i.e., sampling with replacement) which creates a large sample with lower variance than a random sample of the same size. This is an important null finding that may have important implications, so I do not think that it is cause for rejection. However, it is a key element of this paper and I think it should be assessed further and discussed more widely in the abstract and conclusion.
2. The authors state that "83.3% of subjects reported having no or just one binge drinking experience until age 14". To gain clearer insights into the causality, I recommend repeating the MRIage14 → AAMage22 prediction using only these 83% of subjects.
3. The feature importance results for brain regions are quite inconsistent across time points. As such, the study doesn't really address one of the main challenges with previous work discussed in the introduction: "brain regions reported were not consistent between these studies either and do not tell a coherent story". This would be worth looking into further, for example by looking at other indices of feature importance such as permutation-based measures and/or investigating the stability of feature importance across bootstrapped CV folds.
-
Reviewer #2 (Public Review):
The authors extensively compared different phenotypes of alcohol misuse and found that binge drinking is the most predictable phenotype of alcohol misuse, which can be predicted from their brain structure with a significant and high accuracy of 73% − 78%. More importantly, alcohol misuse at age 22 could be predicted from the brains at age 14 and age 19. Two non-linear models - SVM-rbf and GB perform better than the two linear models; and counter-balancing with oversampling is most effective confound-control technique. This work has made substantial experiments to verify the prediction results in long-term, large cohorts of data via a systematic prediction analysis.
-
