Eye movements reveal spatiotemporal dynamics of visually-informed planning in navigation
Curation statements for this article:-
Curated by eLife

Evaluation Summary:
The research conducted examines how the patterns of human eye-movements recorded during the navigation of complex mazes in immersive virtual reality relates to the computational demands of navigating the mazes. A key result is evidence of sweeps to the goal across the maze and back from the goal towards the current location prior to movement, which may help with understanding computational principles of planning. A key strength is its sophisticated computational measures for characterizing the multiple dimensions of eye movement data and the fact this work is novel with few prior studies investigating this important topic. Its findings and methodology are of interest to many areas within cognitive neuroscience, notably decision making and navigation.
(This preprint has been reviewed by eLife. We include the public reviews from the reviewers here; the authors also receive private feedback with suggested changes to the manuscript. Reviewer #2 agreed to share their name with the authors.)
This article has been Reviewed by the following groups
Discuss this preprint
Start a discussion What are Sciety discussions?Listed in
- Evaluated articles (eLife)
Abstract
Goal-oriented navigation is widely understood to depend upon internal maps. Although this may be the case in many settings, humans tend to rely on vision in complex, unfamiliar environments. To study the nature of gaze during visually-guided navigation, we tasked humans to navigate to transiently visible goals in virtual mazes of varying levels of difficulty, observing that they took near-optimal trajectories in all arenas. By analyzing participants’ eye movements, we gained insights into how they performed visually-informed planning. The spatial distribution of gaze revealed that environmental complexity mediated a striking trade-off in the extent to which attention was directed towards two complimentary aspects of the world model: the reward location and task-relevant transitions. The temporal evolution of gaze revealed rapid, sequential prospection of the future path, evocative of neural replay. These findings suggest that the spatiotemporal characteristics of gaze during navigation are significantly shaped by the unique cognitive computations underlying real-world, sequential decision making.
Article activity feed
-

-

Author Response
Reviewer #1 (Public Review):
Zhu et al. found that human participants could plan routes almost optimally in virtual mazes with varying complexity. They further used eye movements as a window to reveal the cognitive computations that may underly such close-to-optimal performance. Participants’ eye movement patterns included: (1) Gazes were attracted to the most task-relevant transitions (effectively the bottleneck transitions) as well as to the goal, with the share of the former increasing with maze complexity; (2) Backward sweeps (gazes moving from goal to start) and forward sweeps (gazes from start to goal) respectively dominated the pre-movement and movement periods, especially in more complex mazes. The authors explained the first pattern as the consequence of efficient strategies of information collection (i.e., …
Author Response
Reviewer #1 (Public Review):
Zhu et al. found that human participants could plan routes almost optimally in virtual mazes with varying complexity. They further used eye movements as a window to reveal the cognitive computations that may underly such close-to-optimal performance. Participants’ eye movement patterns included: (1) Gazes were attracted to the most task-relevant transitions (effectively the bottleneck transitions) as well as to the goal, with the share of the former increasing with maze complexity; (2) Backward sweeps (gazes moving from goal to start) and forward sweeps (gazes from start to goal) respectively dominated the pre-movement and movement periods, especially in more complex mazes. The authors explained the first pattern as the consequence of efficient strategies of information collection (i.e., active sensing) and connected the second pattern to neural replays that relate to planning.
The authors have provided a comprehensive analysis of the eye movement patterns associated with efficient navigation and route planning, which offers novel insights for the area through both their findings and methodology. Overall, the technical quality of the study is high. The "toggling" analysis, the characterization of forward and backward sweeps, and the modeling of observers with different gaze strategies are beautiful. The writing of the manuscript is also elegant.
I do not see any weaknesses that cannot be addressed by extended data analysis or modeling. The following are two major concerns that I hope could be addressed.
We thank the reviewer for their positive assessment of our work!
First, the current eye movement analysis does not seem to have touched the core of planning-evaluating alternative trajectories to the goal. Instead, planning-focused analyses such as forward and backward sweeps were all about the actually executed trajectory. What may participants’ eye movements tell us about their evaluation of alternative trajectories?
This is an important point that we previously overlooked because our experimental design did not incorporate mutually exclusive alternative trajectories. Nonetheless, there are many trials in which participants had access to several possible trajectories to the goal. Some of those alternatives may be trivially suboptimal (e.g. highly convoluted trajectory, taking a slightly curved instead of straight trajectory, or setting out on the wrong path and then turning back). Using two simple constraints described in the Methods (no cyclic paths, limited amount of overlap between alternatives), we algorithmically identified the number of non-trivial alternative trajectories (or options) on each trial that were comparable in length to the chosen trajectory (within about 1 standard deviation). A few examples are shown below for the reviewer.
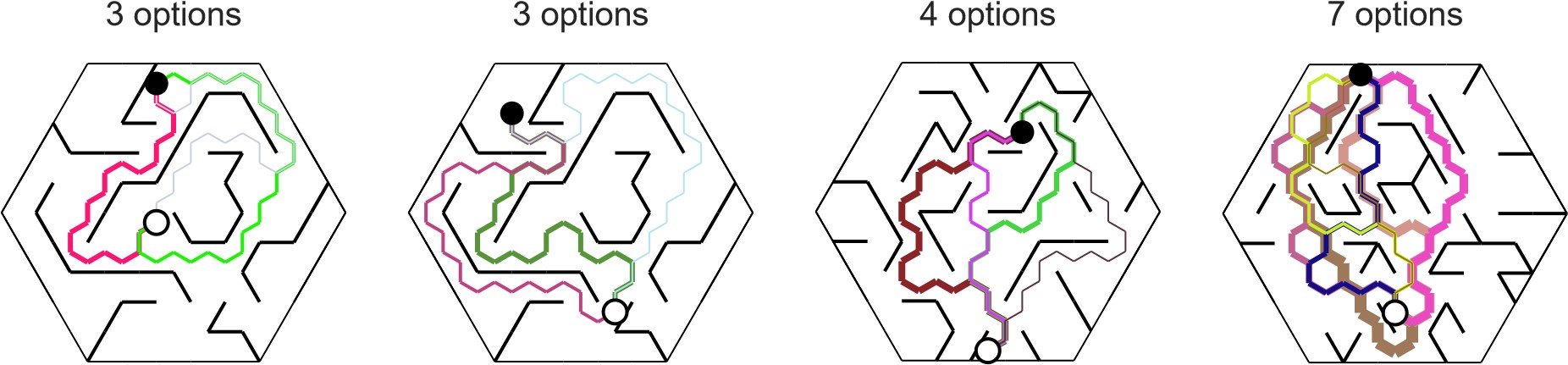
The more plausible trajectory options there were, the more time participants spent gazing upon these alternatives during both pre-movement and movement (Figure 4 – figure supplement 1D – left). This is not a trivial effect resulting from the increase in surface area comprising the alternative paths because the time spent looking at the chosen trajectory also increased with the number of alternatives (Figure S8D – middle). Instead, this suggests that participants might be deliberating between comparable options.
Consistent with this, the likelihood of gazing alternative trajectories peaked early on during pre-movement and well before performing sweeping eye movements (Figure 5D). During movement, the probability of gazing upon alternatives increases immediately before participants make a turn, suggesting that certain aspects of deliberation may also be carried out on the fly just before approaching choice points. Critically, during both pre-movement and movement epochs, the fraction of time spent looking at the goal location decreased with the number of alternatives (Figure 4 – figure supplement 1D – right), revealing a potential trade-off between deliberative processing and looking at the reward location. Future studies with more structured arena designs are needed to better understand the factors that lead to the selection of a particular trajectory among alternatives, and we mention this in the discussion (line 445):
"Value-based decisions are known to involve lengthy deliberation between similar alternatives. Participants exhibited a greater tendency to deliberate between viable alternative trajectories at the expense of looking at the reward location. Likelihood of deliberation was especially high when approaching a turn, suggesting that some aspects of path planning could also be performed on the fly. More structured arena designs with carefully incorporated trajectory options could help shed light on how participants discover a near-optimal path among alternatives. However, we emphasize that deliberative processing accounted for less than onefifth of the spatial variability in eye movements, such that planning largely involved searching for a viable trajectory."
Second, what cognitive computations may underly the observed patterns of eye movements has not received a thorough theoretical treatment. In particular, to explain why participants tended to fixate the bottleneck transitions, the authors hypothesized active sensing, that is, participants were collecting extra visual information to correct their internal model about the maze. Though active sensing is a possible explanation (as demonstrated by the authors’ modeling of "smart" observers), it is not necessarily the only or most parsimonious explanation. It is possible that their peripheral vision allowed participants to form a good-enough model about the maze and their eye movements solely reflect planning. In fact, that replays occur more often at bottleneck states is an emergent property of Mattar & Daw’s (2018) normative theory of neural replay. Forward and backward replays are also emergent properties of their theory. It might be possible to explain all the eye movement patterns-fixating the goal and the bottleneck transitions, and the forward and backward replays-based on Mattar & Daw’s theory in the framework of reinforcement learning. Of course, some additional assumptions that specify eye movements and their functional roles in reinforcement learning (e.g., fixating a location is similar to staying at the corresponding state) would be needed, analogous to those in the authors’ "smart" observer models. This unifying explanation may not only be more parsimonious than the author’s active sensing plus planning account, but also be more consistent with the data than the latter. After all, if participants had used fixations to correct their internal model of the maze, they should not have had little improvements across trials in the same maze.
We thank the reviewer for this reference. We note the strong parallels between our eye movement results and that study in the discussion, in addition to proposing experimental variations that will help crystallize the link. Below, we included our response that was incorporated into the Discussion section (beginning at line 462).
"In [a] highly relevant theoretical work, Mattar and Daw proposed that path planning and structure learning are variants of the same operation, namely the spatiotemporal propagation of memory. The authors show that prioritization of reactivating memories about reward encounters and imminent choices depends upon its utility for future task performance. Through this formulation, the authors provided a normative explanation for the idiosyncrasies of forward and backward replay, the overrepresentation of reward locations and turning points in replayed trajectories, and many other experimental findings in the hippocampus literature. Given the parallels between eye movements and patterns of hippocampal activity, it is conceivable that gaze patterns can be parsimoniously explained as an outcome of such a prioritization scheme. But interpreting eye movements observed in our task in the context of the prioritization theory requires a few assumptions. First, we must assume that traversing a state space using vision yields information that has the same effect on the computation of utility as does information acquired through physical navigation. Second, peripheral vision allows participants to form a good model of the arena such that there is little need for active sensing. In other words, eye movements merely reflect memory access and have no computational role. Finally, long-term statistics of sweeps gradually evolve with exposure, similar to hippocampal replays. These assumptions can be tested in future studies by titrating the precise amount of visual information available to the participants, and by titrating their experience and characterizing gaze over longer exposures. We suspect that a pure prioritization-based account might be sufficient to explain eye movements in relatively uncluttered environments, whereas navigation in complex environments would engage mechanisms involving active inference. Developing an integrative model that features both prioritized memory-access as well as active sensing to refine the contents of memory, would facilitate further understanding of computations underlying sequential decision-making in the presence of uncertainty."
In the original manuscript, we referred to active sensing and planning in order to ground our interpretation in terminology that has been established in previous works by other groups, which had investigated them in isolation. Although the role active sensing could be limited, we are unable to conclude that eye movements solely reflect planning. Even if peripheral vision is sufficient to obtain a good-enough model of the environment, eye movements can further reduce uncertainty about the environment structure especially in cluttered environments such as the complex arena used in this study. This reduction in uncertainty is not inconsistent with a lack of performance improvement across trials. This is because the lack of improvement could be explained by a failure to consolidate the information gathered by eye movements and propagate them across trials, an interpretation that would also explain why planning duration is stable across trials (Figure 2 – figure supplement 2B). Furthermore, participants gaze at alternative trajectories more frequently when more options are presented to them. However we acknowledge that this is a fundamental question, and identified this as an important topic for follow up studies and outline experiments to delineate the precise extent to which eye movements reflect prioritized memory access vs active sensing. Briefly, we can reduce the contribution of active sensing by manipulating the amount of visual information – ranging from no information (navigating in the dark) to partial information (foveated rendering in VR headset). Likewise, we can increase the contribution of memory by manipulating the length of the experiment to ensure participants become fully familiar with the arena. Yet another manipulation is to use a fixed reward location for all trials such that experimental conditions would closely match the simulations of the prioritization model. We are excited about performing these follow up experiments.
Reviewer #2 (Public Review):
In this study the authors sought to understand how the patterns of eye-movements that occur during navigation relate to the cognitive demands of navigating the current environment. To achieve this the authors developed a set of mazes with visible layouts that varied in complexity. Participants navigated these environments seated on a chair by moving in immersive virtual reality.
The question of how eye-movements relate to cognitive demands during navigation is a central and often overlooked aspect of navigating an environment. Study eye-movements in dynamic scenarios that enable systematic analysis is technically challenging, and hence why so few studies have tackled this issue.
The major strengths of this study are the technical development of the set up for studying, recording and analysing the eye-movements. The analysis is extensive and allows greater insight than most studies exploring eye-movements would provide. The manuscript is also well written and argued.
A current weakness of the manuscript is that several other factors have not been considered that may relate to the eye-movements. More consideration of these would be important.
We thank the reviewer for their positive assessment of the innovative aspects of this study. We have tried to address the weaknesses by performing additional analyses described below.
- In the experimental design it appears possible to separate the length of the optimal path from the complexity of the maze. But that appears not to have been done in this design. It would be useful for the authors to comment on this, as these two parameters seem critically important to the interpretation of the role of eye-movements - e.g. a lot of scanning might be required for an obvious, but long path, or a lot of scanning might be required to uncover short path through a complex maze.
This is a great point. We added a comment to the Discussion at line 489 to address this:
"Future work could focus on designing more structured arenas to experimentally separate the effects of path length, number of subgoals, and environmental complexity on participants’ eye movement patterns."
To make the most of our current design, we performed two analyses. First, we regressed trial-specific variables simultaneously against path length and arena complexity. This analysis revealed that the effect of complexity on behavior persists even after accounting for path length differences across arenas (Figure 4 – figure supplement 3). Second, path length is but one of many variables that collectively determine the complexity of the maze. Therefore, we also analyzed the effects of multiple trial-specific variables (number of turns, length of the optimal path, and the degree to which participants are expected to turn back the initial direction of heading to reach the goal, regardless of arena complexity) on eye movements. This revealed fine-grained insights on which task demands most influenced each eye movement quality that was described. More complex arenas posed, on average, greater challenges in terms of longer and more winding trajectories, such that eye movement qualities which increased with arena complexity also generally increased with specific measures of trial difficulty, albeit to varying degrees. We added additional plots to the main/supplementary figures and described these analyses under a new heading (“Linear mixed effects models”) in the Methods section.
- Similarly, it was not clear how the number of alternative plausible paths was considered in the analysis.It seems possible to have a very complex maze with no actual required choices that would involve a lot of scanning to determine this, or a very simple maze with just two very similar choices but which would involve significant scanning to weight up which was indeed the shortest.
Thank you for the suggestion. In conjunction with our response to the first comment from Reviewer #1, we used some constraints to identify non-trivial alternative trajectories – trajectories that pass through different locations in the arena but are roughly similar in length (within about 1 SD of the chosen trajectory). In alignment with your intuition, the most complex maze, as well as the completely open arena, did not have non-trivial alternative trajectories. For the three arenas of medium complexity, the more open arenas had more non-trivial alternative trajectories.
When we analyzed the relative effect of the number of alternative trajectories on eye movement, we found that both possibilities you suggested are true. On trials with many comparable alternatives, participants indeed spend more time scanning the alternatives and less time looking at the goal (Figure S8D). Likewise, in the most complex maze where there are no alternatives, participants still spent much more time (than simpler mazes) learning about the arena structure at the expense of looking at the goal (Figure 3E-F). This analysis yielded interesting new insights into how participants solved the task and opens the door for investigating this trade-off in future work. More generally, because both deliberation and structure learning appear to drive eye movements, they must be factored into studies of human planning.
- Can the affordances linked to turning biases and momentum explain the error patterns? For example,paths that require turning back on the current trajectory direction to reach the goal will be more likely to cause errors, and patterns of eye-movements that might be related to such errors.
Thank you for this question. In conjunction with the trial-specific analyses on the effect of the length of the trajectory (Point #1) on errors and eye movement patterns, we also looked into how the number of turns and the relative bearing (angle between the direction of initial heading and the direction of target approach) affected participants’ behavior. Turns and momentum do not affect the relative error (distance of the stopping location to the target) as much as the trajectory length does, which was unexpected (Figure 1 – figure supplement 1F). This supports that errors were primarily caused by forgetting the target location, and this memory leak gets worse with distance (or time). However, turns have an influence on eye movements in general. For example, more turns generally result in an increase in the fraction of time that participants spend gazing upon the trajectory (Figure 4 – figure supplement 1A) and sweeping (Figure 4D). Furthermore, the number of turns decreased the fraction of time participants spent gazing at the target during movement (Figure 2D).
- Why were half the obstacle transitions miss-remembered for the blind agent? This seems a rather arbitrary choice. More information to justify this would be useful.
We tested out different percentages and found qualitatively similar results. The objective was to determine the patterns of eye movements that would be most beneficial when participants have an intermediate level of knowledge about the arena configuration (rather than near-zero or near-perfect), because during most trials, participants can also use peripheral vision to assess the rough layout, but they do not precisely remember the location of the obstacles. We added this explanation to Appendix 1, where the simulation details have been made in response to a suggestion by another reviewer.
- The description of some of the results could usefully be explained in more simple terms at various pointsto aid readers not so familiar with the RL formation of the task. For example, a key result reported is that participants skew looking at the transition function in complex environments rather than the reward function. It would be useful to relate this to everyday scenarios, in this case broadly to looking more at the junctions in the maze than at the goal, or near the goal, when the maze is complex.
This is a great suggestion. We added an everyday analogy when describing the trade-off on line 258.
"The trade-off reported here is roughly analogous to the trade-off between looking ahead towards where you’re going and having to pay attention to signposts or traffic lights. One could get away with the former strategy while driving on rural highways whereas city streets would warrant paying attention to many other aspects of the environment to get to the destination."
- The authors should comment on their low participant sample size. The sample seems reasonable giventhe reproducibility of the patterns, but it is much lower than most comparable virtual navigation tasks.
Thank you for the recommendation. We had some difficulties recruiting human participants who were willing to wear a headset which had been worn by other participants during COVID-19, and some participants dropped out of the study due to feeling motion sickness. To ameliorate the low sample size, we collected data on four more participants and performed analyses to confirm that the major findings may be observed in most individual participants. Participant-specific effects are included in the new plots made in response to Points # 1-3, and the number of participants with a significant result for each figure/panel has been included as Appendix 2 – table 3.
Reviewer #3 (Public Review):
In this article, Zhu and colleagues studied the role of eye movements in planning in complex environments using virtual reality technology. The main findings are that humans can 1) near optimally navigate in complex environments; 2) gaze data revealed that humans tend to look at the goal location in simple environments, but spend more time on task relevant structures in more complex tasks; 3) human participants show backward and forward sweeping mostly during planning (pre-movement) and execution (movement), respectively.
I think this is a very interesting study with a timely question and is relevant to many areas within cognitive neuroscience, notably decision making, navigation. The virtual reality technology is also quite new for studying planning. The manuscript has been written clearly. This study helps with understanding computational principles of planning. I enjoyed reading this work. I have only one major comment about statistical analyses that I hope authors can address.
We thank the reviewer for the accurate description and positive assessment of our work.
Number of subjects included in analyses in the study is only nine. This is a very small sample size for most human studies. What was the motivation behind it? I believe that most findings are quite robust, but still 9 subjects seems too low. Perhaps authors can replicate their finding in another sample? Alternatively, they might be able to provide statistics per individual and only report those that are significant in all subjects (of course, this only works if reported effects are super robust. But only in such a case 9 subjects are sufficient.)
Thank you for the suggested alternatives. Due to the pandemic, we had some difficulties recruiting human participants who were willing to wear a headset which had been worn by other participants. We collected data on four more participants and included them in the analyses, and also confirmed that the major findings are observed in most individuals. The number of participants with a significant result for each analysis has been included in Figure 1 – figure supplement 3 and Appendix 2 – table 3.
Somewhat related to the previous point, it seems to me that authors have pooled data from all subjects (basically treating them as 1 super-subject?) I am saying this based on the sentence written on page 5, line 130: "Because we are interested in principles that are conserved across subjects, we pooled subjects for all subsequent analyses." If this is not the case, please clarify that (and also add a section on "statistical analyses" in Methods.) But if this is the case, it is very problematic, because it means that statistical analyses are all done based on a fixed-effect approach. The fixed effect approach is infamous for inflated type I error.
Your interpretation is correct and we acknowledge your concern about pooling participants. We had done this after observing that our results were consistent across participants but this was not demonstrated. We have now performed analyses sensitive to participant-specific effects and find that all major results hold for most participants, and we included additional main and supplementary bar plots (and tables in Appendix 2) showing per-participant data. The new plots/table show the effect of independent variables (mainly trial/arena difficulty) on dependent variables for each participant, as well as general effects conserved across participants. A new paragraph was added to the Methods section to describe the “Linear mixed effects models” which we used.
Again, quite related to the last two points: please include degrees of freedom for every statistical test (i.e. every reported p-value).
Degrees of freedom (df) are now included along with each p-value.
-
Evaluation Summary:
The research conducted examines how the patterns of human eye-movements recorded during the navigation of complex mazes in immersive virtual reality relates to the computational demands of navigating the mazes. A key result is evidence of sweeps to the goal across the maze and back from the goal towards the current location prior to movement, which may help with understanding computational principles of planning. A key strength is its sophisticated computational measures for characterizing the multiple dimensions of eye movement data and the fact this work is novel with few prior studies investigating this important topic. Its findings and methodology are of interest to many areas within cognitive neuroscience, notably decision making and navigation.
(This preprint has been reviewed by eLife. We include the public …
Evaluation Summary:
The research conducted examines how the patterns of human eye-movements recorded during the navigation of complex mazes in immersive virtual reality relates to the computational demands of navigating the mazes. A key result is evidence of sweeps to the goal across the maze and back from the goal towards the current location prior to movement, which may help with understanding computational principles of planning. A key strength is its sophisticated computational measures for characterizing the multiple dimensions of eye movement data and the fact this work is novel with few prior studies investigating this important topic. Its findings and methodology are of interest to many areas within cognitive neuroscience, notably decision making and navigation.
(This preprint has been reviewed by eLife. We include the public reviews from the reviewers here; the authors also receive private feedback with suggested changes to the manuscript. Reviewer #2 agreed to share their name with the authors.)
-
Reviewer #1 (Public Review):
Zhu et al. found that human participants could plan routes almost optimally in virtual mazes with varying complexity. They further used eye movements as a window to reveal the cognitive computations that may underly such close-to-optimal performance. Participants' eye movement patterns included: (1) Gazes were attracted to the most task-relevant transitions (effectively the bottleneck transitions) as well as to the goal, with the share of the former increasing with maze complexity; (2) Backward sweeps (gazes moving from goal to start) and forward sweeps (gazes from start to goal) respectively dominated the pre-movement and movement periods, especially in more complex mazes. The authors explained the first pattern as the consequence of efficient strategies of information collection (i.e., active sensing) and …
Reviewer #1 (Public Review):
Zhu et al. found that human participants could plan routes almost optimally in virtual mazes with varying complexity. They further used eye movements as a window to reveal the cognitive computations that may underly such close-to-optimal performance. Participants' eye movement patterns included: (1) Gazes were attracted to the most task-relevant transitions (effectively the bottleneck transitions) as well as to the goal, with the share of the former increasing with maze complexity; (2) Backward sweeps (gazes moving from goal to start) and forward sweeps (gazes from start to goal) respectively dominated the pre-movement and movement periods, especially in more complex mazes. The authors explained the first pattern as the consequence of efficient strategies of information collection (i.e., active sensing) and connected the second pattern to neural replays that relate to planning.
The authors have provided a comprehensive analysis of the eye movement patterns associated with efficient navigation and route planning, which offers novel insights for the area through both their findings and methodology. Overall, the technical quality of the study is high. The "toggling" analysis, the characterization of forward and backward sweeps, and the modeling of observers with different gaze strategies are beautiful. The writing of the manuscript is also elegant.
I do not see any weaknesses that cannot be addressed by extended data analysis or modeling. The following are two major concerns that I hope could be addressed.
First, the current eye movement analysis does not seem to have touched the core of planning-evaluating *alternative* trajectories to the goal. Instead, planning-focused analyses such as forward and backward sweeps were all about the actually executed trajectory. What may participants' eye movements tell us about their evaluation of alternative trajectories?
Second, what cognitive computations may underly the observed patterns of eye movements has not received a thorough theoretical treatment. In particular, to explain why participants tended to fixate the bottleneck transitions, the authors hypothesized active sensing, that is, participants were collecting extra visual information to correct their internal model about the maze. Though active sensing is a possible explanation (as demonstrated by the authors' modeling of "smart" observers), it is not necessarily the only or most parsimonious explanation. It is possible that their peripheral vision allowed participants to form a good-enough model about the maze and their eye movements solely reflect planning. In fact, that replays occur more often at bottleneck states is an emergent property of Mattar & Daw's (2018) normative theory of neural replay. Forward and backward replays are also emergent properties of their theory. It might be possible to explain all the eye movement patterns-fixating the goal and the bottleneck transitions, and the forward and backward replays-based on Mattar & Daw's theory in the framework of reinforcement learning. Of course, some additional assumptions that specify eye movements and their functional roles in reinforcement learning (e.g., fixating a location is similar to staying at the corresponding state) would be needed, analogous to those in the authors' "smart" observer models. This unifying explanation may not only be more parsimonious than the author's active sensing plus planning account, but also be more consistent with the data than the latter. After all, if participants had used fixations to correct their internal model of the maze, they should not have had little improvements across trials in the same maze.
Reference:
Mattar, M. G., & Daw, N. D. (2018). Prioritized memory access explains planning and hippocampal replay. Nature Neuroscience. https://doi.org/10.1038/s41593-018-0232-z -
Reviewer #2 (Public Review):
In this study the authors sought to understand how the patterns of eye-movements that occur during navigation relate to the cognitive demands of navigating the current environment. To achieve this the authors developed a set of mazes with visible layouts that varied in complexity. Participants navigated these environments seated on a chair by moving in immersive virtual reality.
The question of how eye-movements relate to cognitive demands during navigation is a central and often overlooked aspect of navigating an environment. Study eye-movements in dynamic scenarios that enable systematic analysis is technically challenging, and hence why so few studies have tackled this issue.
The major strengths of this study are the technical development of the set up for studying, recording and analysing the …
Reviewer #2 (Public Review):
In this study the authors sought to understand how the patterns of eye-movements that occur during navigation relate to the cognitive demands of navigating the current environment. To achieve this the authors developed a set of mazes with visible layouts that varied in complexity. Participants navigated these environments seated on a chair by moving in immersive virtual reality.
The question of how eye-movements relate to cognitive demands during navigation is a central and often overlooked aspect of navigating an environment. Study eye-movements in dynamic scenarios that enable systematic analysis is technically challenging, and hence why so few studies have tackled this issue.
The major strengths of this study are the technical development of the set up for studying, recording and analysing the eye-movements. The analysis is extensive and allows greater insight than most studies exploring eye-movements would provide. The manuscript is also well written and argued.
A current weakness of the manuscript is that several other factors have not been considered that may relate to the eye-movements. More consideration of these would be important.
1. In the experimental design it appears possible to separate the length of the optimal path from the complexity of the maze. But that appears not to have been done in this design. It would be useful for the authors to comment on this, as these two parameters seem critically important to the interpretation of the role of eye-movements - e.g. a lot of scanning might be required for an obvious, but long path, or a lot of scanning might be required to uncover short path through a complex maze.
2. Similarly, it was not clear the how the number of alternative plausible paths was considered in the analysis. It seems possible to have a very complex maze with no actual required choices that would involve a lot of scanning to determine this, or a very simple maze with just two very similar choices but which would involve significant scanning to weight up which was indeed the shortest.
3. Can the affordances linked to turning biases and momentum explain the error patterns? For example, paths that require turning back on the current trajectory direction to reach the goal will be more likely to cause errors, and patterns of eye-movement that might related to such errors.
4. Why were half the obstacle transitions miss-remembered for the blind agent? This seems a rather arbitrary choice. More information to justify this would be useful.
5. The description of some the results could usefully be explained in more simple terms at various points to aid readers not so familiar with the RL formation of the task. For example, a key result reported is that participants skew looking at the transition function in complex environments rather than the reward function. It would be useful to relate this to everyday scenarios, in this case broadly to looking more at the junctions in the maze than at the goal, or near the goal, when the maze is complex.
6. The authors should comment on their low participant sample size. The sample seems reasonable given the reproducibility of the patterns, but it is much lower than most comparable virtual navigation tasks.
The authors have generally achieved their aim. The results appear compelling and with further consideration of the results, the findings should lead to an important research article helping advance a key aspect of navigation - how eye-movements are related to cognitive processes involved in solving the path choices in navigation.
An impact of this work is that it should encourage models of the neural system of navigation to predict how eye-movements will occur during navigation and opens the potential for eye-movements to be used in a wide range of studies of virtual or real-world navigation.
-
Reviewer #3 (Public Review):
In this article, Zhu and colleagues studied the role of eye movements in planning in complex environments using virtual reality technology. The main findings are that humans can 1) near optimally navigate in complex environments; 2) gaze data revealed that humans tend to look at the goal location in simple environments, but spend more time on task relevant structures in more complex tasks; 3) human participants show backward and forward sweeping mostly during planning (pre-movement) and execution (movement), respectively.
I think this is a very interesting study with a timely question and is relevant to many areas within cognitive neuroscience, notably decision making, navigation. The virtual reality technology is also quite new for studying planning. The manuscript has been written clearly. This study helps …
Reviewer #3 (Public Review):
In this article, Zhu and colleagues studied the role of eye movements in planning in complex environments using virtual reality technology. The main findings are that humans can 1) near optimally navigate in complex environments; 2) gaze data revealed that humans tend to look at the goal location in simple environments, but spend more time on task relevant structures in more complex tasks; 3) human participants show backward and forward sweeping mostly during planning (pre-movement) and execution (movement), respectively.
I think this is a very interesting study with a timely question and is relevant to many areas within cognitive neuroscience, notably decision making, navigation. The virtual reality technology is also quite new for studying planning. The manuscript has been written clearly. This study helps with understanding computational principles of planning. I enjoyed reading this work. I have only one major comment about statistical analyses that I hope authors can address.
Number of subjects included in analyses in the study is only nine. This is a very small sample size for most human studies. What was the motivation behind it? I believe that most findings are quite robust, but still 9 subjects seems too low. Perhaps authors can replicate their finding in another sample? Alternatively, they might be able to provide statistics per individual and only report those that are significant in all subjects (of course, this only works if reported effects are super robust. But only in such a case 9 subjects are sufficient.)
Somewhat related to the previous point, it seems to me that authors have pooled data from all subjects (basically treating them as 1 super-subject?) I am saying this based on the sentence written on page 5, line 130: "Because we are interested in principles that are conserved across subjects, we pooled subjects for all subsequent analyses."
If this is not the case, please clarify that (and also add a section on "statistical analyses" in Methods.) But if this is the case, it is very problematic, because it means that statistical analyses are all done based on a fixed-effect approach. The fixed effect approach is infamous for inflated type I error.Again, quite related to the last two points: please include degrees of freedom for every statistical test (i.e. every reported p-value).
-
