Endogenous Precision of the Number Sense
Curation statements for this article:-
Curated by eLife

eLife Assessment
This important research investigates the precision of numerosity perception in two types of tasks and concludes that human performance aligns with an efficient coding model optimized for current environmental statistics and task goals. The proposed model receives compelling evidence from two numerosity perception experiments and a reanalysis of an existing dataset of risky decision-making. These findings have theoretical implications for our understanding of numerosity perception and decision-making as well as the ongoing debate on different efficient coding models.
This article has been Reviewed by the following groups
Discuss this preprint
Start a discussion What are Sciety discussions?Listed in
- Evaluated articles (eLife)
Abstract
The behavioral variability in psychophysical experiments and the stochasticity of sensory neurons have revealed the inherent imprecision in the brain’s representations of environmental variables1–6. Numerosity studies yield similar results, pointing to an imprecise ‘number sense’ in the brain7–13. If the imprecision in representations reflects an optimal allocation of limited cognitive resources, as suggested by efficient-coding models14–26, then it should depend on the context in which representations are elicited25,27. Through an estimation task and a discrimination task, both involving numerosities, we show that the scale of subjects’ imprecision increases, but sublinearly, with the width of the prior distribution from which numbers are sampled. This sublinear relation is notably different in the two tasks. The double dependence of the imprecision — both on the prior and on the task — is consistent with the optimization of a tradeoff between the expected reward, different for each task, and a resource cost of the encoding neurons’ activity. Comparing the two tasks allows us to clarify the form of the resource constraint. Our results suggest that perceptual noise is endogenously determined, and that the precision of percepts varies both with the context in which they are elicited, and with the observer’s objective.
Article activity feed
-

-
-

eLife Assessment
This important research investigates the precision of numerosity perception in two types of tasks and concludes that human performance aligns with an efficient coding model optimized for current environmental statistics and task goals. The proposed model receives compelling evidence from two numerosity perception experiments and a reanalysis of an existing dataset of risky decision-making. These findings have theoretical implications for our understanding of numerosity perception and decision-making as well as the ongoing debate on different efficient coding models.
-
Reviewer #3 (Public review):
Summary:
This work investigates whether human imprecision in numeric perception is a fixed structural constraint or an endogenous property that adapts to environmental statistics and task objectives. By measuring behavioral variability across different uniform prior distributions in both estimation and discrimination tasks, the authors show that perceptual imprecision increases sublinearly with prior width. They demonstrate that the specific exponents of this scaling (1/2 for estimation and 3/4 for discrimination) can be derived from an efficient-coding model, wherein decision-makers optimally balance task-specific expected rewards against the metabolic costs of neural coding. The revised manuscript expands this framework to accommodate logarithmic representations and validates the core model against an …
Reviewer #3 (Public review):
Summary:
This work investigates whether human imprecision in numeric perception is a fixed structural constraint or an endogenous property that adapts to environmental statistics and task objectives. By measuring behavioral variability across different uniform prior distributions in both estimation and discrimination tasks, the authors show that perceptual imprecision increases sublinearly with prior width. They demonstrate that the specific exponents of this scaling (1/2 for estimation and 3/4 for discrimination) can be derived from an efficient-coding model, wherein decision-makers optimally balance task-specific expected rewards against the metabolic costs of neural coding. The revised manuscript expands this framework to accommodate logarithmic representations and validates the core model against an independent dataset of risky choices.
Strengths:
The authors have effectively addressed my previous concerns with rigorous additions:
(1) The mathematical formulation has been revised into a discrete signal accumulation framework, making the objective function and resource trade-offs much more transparent and mathematically tractable.
(2) The incorporation of the logarithmic representation resolves prior ambiguities regarding structural constraints.
(3) The new split-half analysis effectively addresses the temporal dynamics of adaptation. The stability of the sublinear scaling across the experiment provides solid evidence that human subjects utilize rapid, top-down modulation to adjust their encoding strategy when explicitly informed about the environment.
(4) Validating the derived scaling exponents on an independent risky-choice dataset robustly supports the generalizability of the theoretical framework beyond a single cognitive domain.
Comments on revisions:
The authors have addressed my remaining theoretical concern regarding the model's predictions for mean estimation bias. I have no further comments.
-
Author response:
The following is the authors’ response to the previous reviews
Public Reviews:
Reviewer #1 (Public review):
Summary:
The "number sense" refers to an imprecise and noisy representation of number. Many researchers propose that the number sense confers a fixed (exogenous) subjective representation of number that adheres to scalar variability, whereby the variance of the representation of number is linear in the number.
This manuscript investigates whether the representation of number is fixed, as usually assumed in the literature, or whether it is endogenous. The two dimensions on which the authors investigate this endogeneity are the subject's prior beliefs about stimuli values and the task objective. Using two experimental tasks, the authors collect data that are shown to violate scalar variability and are instead …
Author response:
The following is the authors’ response to the previous reviews
Public Reviews:
Reviewer #1 (Public review):
Summary:
The "number sense" refers to an imprecise and noisy representation of number. Many researchers propose that the number sense confers a fixed (exogenous) subjective representation of number that adheres to scalar variability, whereby the variance of the representation of number is linear in the number.
This manuscript investigates whether the representation of number is fixed, as usually assumed in the literature, or whether it is endogenous. The two dimensions on which the authors investigate this endogeneity are the subject's prior beliefs about stimuli values and the task objective. Using two experimental tasks, the authors collect data that are shown to violate scalar variability and are instead consistent with a model of optimal encoding and decoding, where the encoding phase depends endogenously on prior and task objectives. I believe the paper asks a critically important question. The literature in cognitive science, psychology, and increasingly in economics, has provided growing empirical evidence of decision-making consistent with efficient coding. However, the precise model mechanics can differ substantially across studies. This point was made forcefully in a paper by Ma and Woodford (2020, Behavioral & Brain Sciences), who argue that different researchers make different assumptions about the objective function and resource constraints across efficient coding models, leading to a proliferation of different models with ad-hoc assumptions. Thus, the possibility that optimal coding depends endogenously on the prior and the objective of the task, opens the door to a more parsimonious framework in which assumptions of the model can be constrained by environmental features. Along these lines, one of the authors' conclusions is that the degree of variability in subjective responses increases sublinearly in the width of the prior. And importantly, the degree of this sublinearity differs across the two tasks, in a manner that is consistent with a unified efficient coding model.
Comments on revisions:
The authors have done an excellent job addressing my main concerns from the previous round. The new analyses that address the alternative model of "no cognitive noise and only motor noise" are compelling and provide quantitative evidence that bolsters the paper's overall contribution. The authors also went above and beyond by reanalyzing the Frydman and Jin (2022) dataset to provide new and very interesting analyses that provide an additional out of sample test of the model proposed in the current paper.
Reviewer #2 (Public review):
Summary:
This paper provides an ingenious experimental test of an efficient coding objective based on optimization as a task success. The key idea is that different tasks (estimation vs discrimination) will, under the proposed model, lead to a different scaling between the encoding precision and the width of the prior distribution. Empirical evidence in two tasks involving number perception supports this idea.
Strengths:
- The paper provides an elegant test of a prediction made by a certain class of efficient coding models previously investigated theoretically by the authors. The results in experiments and modeling suggest that competing efficient coding models, optimizing mutual information alone, may be incomplete by missing the role of the task.
- The paper carefully considers how the novel predictions of the model interact with the Weber/Fechner law.
Weaknesses:
The claims would be even more strongly validated if data were present at more than two widths in the discrimination experiment (also noted in Discussion).
Reviewer #3 (Public review):
Summary:
This work investigates whether human imprecision in numeric perception is a fixed structural constraint or an endogenous property that adapts to environmental statistics and task objectives. By measuring behavioral variability across different uniform prior distributions in both estimation and discrimination tasks, the authors show that perceptual imprecision increases sublinearly with prior width. They demonstrate that the specific exponents of this scaling (1/2 for estimation and 3/4 for discrimination) can be derived from an efficient-coding model, wherein decision-makers optimally balance task-specific expected rewards against the metabolic costs of neural coding. The revised manuscript expands this framework to accommodate logarithmic representations and validates the core model against an independent dataset of risky choices.
Strengths:
The authors have effectively addressed my previous concerns with rigorous additions:
(1) The mathematical formulation has been revised into a discrete signal accumulation framework, making the objective function and resource trade-offs much more transparent and mathematically tractable.
(2) The incorporation of the logarithmic representation resolves prior ambiguities regarding structural constraints.
(3) The new split-half analysis effectively addresses the temporal dynamics of adaptation. The stability of the sublinear scaling across the experiment provides solid evidence that human subjects utilize rapid, top-down modulation to adjust their encoding strategy when explicitly informed about the environment.
(4) Validating the derived scaling exponents on an independent risky-choice dataset robustly supports the generalizability of the theoretical framework beyond a single cognitive domain.
Weaknesses:
The methodological and theoretical issues raised in the first round have been thoroughly resolved, and the evidence supporting the claims regarding response variance is convincing.
There is one remaining theoretical point that warrants discussion to provide a complete picture of the proposed generative model. The manuscript exquisitely models and predicts response variance (imprecision), but it remains largely silent on the closed-form predictions for the mean estimation (i.e., bias). Under the assumption of optimal Bayesian decoding combined with specific encoding schemes (e.g., linear vs. logarithmic), the model implicitly generates mathematical predictions for the subjects' mean estimates. Specifically, varying the scaling exponent (α) and the prior width (w) should systematically alter the predicted bias in different conditions.
While fitting or explicitly explaining this mean bias is not strictly necessary for the core claims regarding variance scaling, acknowledging what the optimal decoder analytically predicts for the mean estimation-and how it aligns or contrasts with typical empirical observations-would strengthen the theoretical transparency of the paper.
We thank the reviewers for their attention to our revised manuscript. We are very glad that the reviewers seem satisfied with how we have addressed their concerns. The paper is now stronger than in its first iteration.
Recommendations for the authors:
Reviewer #1 (Recommendations for the authors):
I have no further requests for the authors, I congratulate the authors on a great paper.
Reviewer #2 (Recommendations for the authors):
No further suggestions.
Reviewer #3 (Recommendations for the authors):
In the Figure 2b caption, the phrase "from which the numbers of dots are sampled" appears to be a typo carried over from the estimation task. It should likely read "from which the numbers are sampled", as the discrimination task uses Arabic numerals rather than dot arrays.
We thank the reviewers for their attention to our revised manuscript. We are very glad that the reviewers seem satisfied with how we have addressed their concerns. The paper is now stronger than in its first iteration.
Reviewer #3 points out that we have focused on the subjects’ response variability, and we did not report the mean estimates. We agree that the reader could reasonably expect to see this. We now include this in Figure 6.
The subjects exhibit the typical patterns observed in numerosity-estimation task (most notably, the ‘central tendency of judgment’). The dotted line shows the predictions of the best-fitting model (with 𝛼 = 1/2) with the logarithmic encoding, which reproduces the subjects’ main behavioral patterns.
We have slightly revised the manuscript. The revised version includes this Figure, in Methods (p. 28). We have modified the text of the Methods accordingly (bottom of p. 27), and we now refer to this analysis in the main text (line 6 of p. 5). We have also corrected the typo noted by Reviewer #3 (caption of Fig. 2b).
-
-
eLife Assessment
This important research investigates the precision of numerosity perception in two types of tasks and concludes that human performance aligns with an efficient coding model optimized for current environmental statistics and task goals. The proposed model receives compelling evidence from two numerosity perception experiments and a reanalysis of an existing dataset of risky decision-making. These findings have theoretical implications for our understanding of numerosity perception and decision-making as well as the ongoing debate on different efficient coding models.
-
Reviewer #1 (Public review):
Summary:
The "number sense" refers to an imprecise and noisy representation of number. Many researchers propose that the number sense confers a fixed (exogenous) subjective representation of number that adheres to scalar variability, whereby the variance of the representation of number is linear in the number.
This manuscript investigates whether the representation of number is fixed, as usually assumed in the literature, or whether it is endogenous. The two dimensions on which the authors investigate this endogeneity are the subject's prior beliefs about stimuli values and the task objective. Using two experimental tasks, the authors collect data that are shown to violate scalar variability and are instead consistent with a model of optimal encoding and decoding, where the encoding phase depends …
Reviewer #1 (Public review):
Summary:
The "number sense" refers to an imprecise and noisy representation of number. Many researchers propose that the number sense confers a fixed (exogenous) subjective representation of number that adheres to scalar variability, whereby the variance of the representation of number is linear in the number.
This manuscript investigates whether the representation of number is fixed, as usually assumed in the literature, or whether it is endogenous. The two dimensions on which the authors investigate this endogeneity are the subject's prior beliefs about stimuli values and the task objective. Using two experimental tasks, the authors collect data that are shown to violate scalar variability and are instead consistent with a model of optimal encoding and decoding, where the encoding phase depends endogenously on prior and task objectives. I believe the paper asks a critically important question. The literature in cognitive science, psychology, and increasingly in economics, has provided growing empirical evidence of decision-making consistent with efficient coding. However, the precise model mechanics can differ substantially across studies. This point was made forcefully in a paper by Ma and Woodford (2020, Behavioral & Brain Sciences), who argue that different researchers make different assumptions about the objective function and resource constraints across efficient coding models, leading to a proliferation of different models with ad-hoc assumptions. Thus, the possibility that optimal coding depends endogenously on the prior and the objective of the task, opens the door to a more parsimonious framework in which assumptions of the model can be constrained by environmental features. Along these lines, one of the authors' conclusions is that the degree of variability in subjective responses increases sublinearly in the width of the prior. And importantly, the degree of this sublinearity differs across the two tasks, in a manner that is consistent with a unified efficient coding model.
Comments on revisions:
The authors have done an excellent job addressing my main concerns from the previous round. The new analyses that address the alternative model of "no cognitive noise and only motor noise" are compelling and provide quantitative evidence that bolsters the paper's overall contribution. The authors also went above and beyond by reanalyzing the Frydman and Jin (2022) dataset to provide new and very interesting analyses that provide an additional out of sample test of the model proposed in the current paper.
-
Reviewer #2 (Public review):
Summary:
This paper provides an ingenious experimental test of an efficient coding objective based on optimization as a task success. The key idea is that different tasks (estimation vs discrimination) will, under the proposed model, lead to a different scaling between the encoding precision and the width of the prior distribution. Empirical evidence in two tasks involving number perception supports this idea.
Strengths:
- The paper provides an elegant test of a prediction made by a certain class of efficient coding models previously investigated theoretically by the authors.
The results in experiments and modeling suggest that competing efficient coding models, optimizing mutual information alone, may be incomplete by missing the role of the task.- The paper carefully considers how the novel predictions of …
Reviewer #2 (Public review):
Summary:
This paper provides an ingenious experimental test of an efficient coding objective based on optimization as a task success. The key idea is that different tasks (estimation vs discrimination) will, under the proposed model, lead to a different scaling between the encoding precision and the width of the prior distribution. Empirical evidence in two tasks involving number perception supports this idea.
Strengths:
- The paper provides an elegant test of a prediction made by a certain class of efficient coding models previously investigated theoretically by the authors.
The results in experiments and modeling suggest that competing efficient coding models, optimizing mutual information alone, may be incomplete by missing the role of the task.- The paper carefully considers how the novel predictions of the model interact with the Weber/Fechner law.
Weaknesses:
- The claims would be even more strongly validated if data were present at more than two widths in the discrimination experiment (also noted in Discussion).
-
Reviewer #3 (Public review):
Summary:
This work investigates whether human imprecision in numeric perception is a fixed structural constraint or an endogenous property that adapts to environmental statistics and task objectives. By measuring behavioral variability across different uniform prior distributions in both estimation and discrimination tasks, the authors show that perceptual imprecision increases sublinearly with prior width. They demonstrate that the specific exponents of this scaling (1/2 for estimation and 3/4 for discrimination) can be derived from an efficient-coding model, wherein decision-makers optimally balance task-specific expected rewards against the metabolic costs of neural coding. The revised manuscript expands this framework to accommodate logarithmic representations and validates the core model against an …
Reviewer #3 (Public review):
Summary:
This work investigates whether human imprecision in numeric perception is a fixed structural constraint or an endogenous property that adapts to environmental statistics and task objectives. By measuring behavioral variability across different uniform prior distributions in both estimation and discrimination tasks, the authors show that perceptual imprecision increases sublinearly with prior width. They demonstrate that the specific exponents of this scaling (1/2 for estimation and 3/4 for discrimination) can be derived from an efficient-coding model, wherein decision-makers optimally balance task-specific expected rewards against the metabolic costs of neural coding. The revised manuscript expands this framework to accommodate logarithmic representations and validates the core model against an independent dataset of risky choices.
Strengths:
The authors have effectively addressed my previous concerns with rigorous additions:
(1) The mathematical formulation has been revised into a discrete signal accumulation framework, making the objective function and resource trade-offs much more transparent and mathematically tractable.
(2) The incorporation of the logarithmic representation resolves prior ambiguities regarding structural constraints.
(3) The new split-half analysis effectively addresses the temporal dynamics of adaptation. The stability of the sublinear scaling across the experiment provides solid evidence that human subjects utilize rapid, top-down modulation to adjust their encoding strategy when explicitly informed about the environment.
(4) Validating the derived scaling exponents on an independent risky-choice dataset robustly supports the generalizability of the theoretical framework beyond a single cognitive domain.
Weaknesses:
The methodological and theoretical issues raised in the first round have been thoroughly resolved, and the evidence supporting the claims regarding response variance is convincing.
There is one remaining theoretical point that warrants discussion to provide a complete picture of the proposed generative model. The manuscript exquisitely models and predicts response variance (imprecision), but it remains largely silent on the closed-form predictions for the mean estimation (i.e., bias). Under the assumption of optimal Bayesian decoding combined with specific encoding schemes (e.g., linear vs. logarithmic), the model implicitly generates mathematical predictions for the subjects' mean estimates. Specifically, varying the scaling exponent (α) and the prior width (w) should systematically alter the predicted bias in different conditions.
While fitting or explicitly explaining this mean bias is not strictly necessary for the core claims regarding variance scaling, acknowledging what the optimal decoder analytically predicts for the mean estimation-and how it aligns or contrasts with typical empirical observations-would strengthen the theoretical transparency of the paper.
-
Author response:
The following is the authors’ response to the original reviews
Public Reviews:
Reviewer #1 (Public review):
Summary:
The "number sense" refers to an imprecise and noisy representation of number. Many researchers propose that the number sense confers a fixed (exogenous) subjective representation of number that adheres to scalar variability, whereby the variance of the representation of number is linear in the number.
This manuscript investigates whether the representation of number is fixed, as usually assumed in the literature, or whether it is endogenous. The two dimensions on which the authors investigate this endogeneity are the subject's prior beliefs about stimuli values and the task objective. Using two experimental tasks, the authors collect data that are shown to violate scalar variability and are instead …
Author response:
The following is the authors’ response to the original reviews
Public Reviews:
Reviewer #1 (Public review):
Summary:
The "number sense" refers to an imprecise and noisy representation of number. Many researchers propose that the number sense confers a fixed (exogenous) subjective representation of number that adheres to scalar variability, whereby the variance of the representation of number is linear in the number.
This manuscript investigates whether the representation of number is fixed, as usually assumed in the literature, or whether it is endogenous. The two dimensions on which the authors investigate this endogeneity are the subject's prior beliefs about stimuli values and the task objective. Using two experimental tasks, the authors collect data that are shown to violate scalar variability and are instead consistent with a model of optimal encoding and decoding, where the encoding phase depends endogenously on prior and task objectives. I believe the paper asks a critically important question. The literature in cognitive science, psychology, and increasingly in economics, has provided growing empirical evidence of decisionmaking consistent with efficient coding. However, the precise model mechanics can differ substantially across studies. This point was made forcefully in a paper by Ma and Woodford (2020, Behavioral & Brain Sciences), who argue that different researchers make different assumptions about the objective function and resource constraints across efficient coding models, leading to a proliferation of different models with ad-hoc assumptions. Thus, the possibility that optimal coding depends endogenously on the prior and the objective of the task, opens the door to a more parsimonious framework in which assumptions of the model can be constrained by environmental features. Along these lines, one of the authors' conclusions is that the degree of variability in subjective responses increases sublinearly in the width of the prior. And importantly, the degree of this sublinearity differs across the two tasks, in a manner that is consistent with a unified efficient coding model.
We thank Reviewer #1 for her/his comments and for placing our work in a broader context.
Comments:
(1) Modeling and implementation of estimation task
The biggest concern I have with the paper is about the experimental implementation and theoretical account of the estimation task. The salient features of the experimental data (Figure 1C) are that the standard deviations of subjects' estimated quantities are hump-shaped in the true stimulus x and that the standard deviation, conditional on the true stimulus x, is increasing in prior width. The authors attribute these features to a Bayesian encoding and decoding model in which the internal representation of the quantity is noisy, and the degree of noise depends on the prior - as in models of efficient coding (Wei and Stocker 2015 Nature Neuro; Bhui and Gershman 2018 Psych Review; Hahn and Wei 2024 Nature Neuro).
The concern I have is about the final "step" in the model, where the authors assume there is an additional layer of motor noise in selecting the response. The authors posit that the subject's selection of the response is drawn from a Gaussian with a mean set to the optimally decoded estimate x*(r), and variance set to a free parameter sigma_0^2. However, the authors also assume that the Gaussian distribution is "truncated to the prior range." This truncation is a nontrivial assumption, and I believe that on its own, it can explain many features of the data.
To see this, assume that there is no noise in the internal representation of x, there is only motor noise. This corresponds to a special case of the authors' model in which υ is set to 0. The model then reduces to a simple account in which responses are drawn from a Gaussian distribution centered at the true value of x, but with asymmetric noise due to the truncation. I simulated such a model with sigma_0=7. The resulting standard deviations of responses for each value of x (based on 1000 draws for each value of x), across the three different priors, reproduce the salient patterns of the standard deviation in Figure 1C: i) within each condition, the standard deviation is hump-shaped and peaks at x=60 and ii) conditional on x, standard deviation increases in prior width. The takeaway is that this simple model with only truncated motor noise - and without any noisy or efficient coding of internal representations - provides an alternative channel through which the prior affects behavior.
Of course, this does not imply that subjects' coding is not described by the efficient encoding and decoding model posited by the authors. However, it does suggest an important alternative mechanism for the authors' theoretical results in the estimation task. Moreover, some of the quantitative conclusions about the differences in behavior with the discrimination task would be greatly affected by the assumption of truncated motor noise.
Turning to the experiment, a basic question is whether such a truncation was actually implemented in the design. That is, was the range of the slider bar set to the range of the prior? (The methods section states that the size on the screen of the slider was proportional to the prior width, but it was unclear whether the bounds of the slider bar changed with the prior). If the slider bar range did depend on the prior, then it becomes difficult to interpret the data. If not, then perhaps one can perform analyses to understand how much the motor noise is responsible for the dependence of the standard deviation on both x and the prior width. Indeed, the authors emphasize that their model is best fit at α=0.48, which would seem to imply that the best fitting value of υ is strictly positive. However, it would be important to clarify whether the estimation procedure allowed for υ=0, or whether this noise parameter was constrained to be positive (i.e., clarify whether the estimation assumed noisy and efficient coding of internal representations).
We thank Reviewer #1 for her/his close attention to the motor-noise component of our model, in particular its truncation at the border of the prior. We agree that the truncated motor noise should be examined more closely as it affects the variance of responses. We address here the questions raised by the reviewer, and we detail the new analyses we have conducted.
First, regarding the experimental paradigm, we note that this truncation was indeed implemented in the design, i.e., the range of the slider bar corresponded to the range of the prior (we now indicate this more clearly in the manuscript). Subjects thus were not able to select an estimate that was not in the support of the prior, and it is precisely for this reason that we model the selection step with a truncated distribution, so that the model is consistent with the experimental setup. This truncation naturally decreases the response variability near the bounds, and this may affect differently the overall variability for the different priors, as noted by the reviewer in her/his simulations. We have conducted a series of analysis to investigate this question.
First, we consider a model in which there is no cognitive noise, but only motor noise. To answer one of the reviewer’s questions, the model-fitting procedure did allow for a vanishing cognitive noise (𝜈 = 0), i.e., it allowed for such a “motor-noise-only” mechanism to be the main account of the data. This value (𝜈 = 0), however, does not maximize the likelihood of the model, and thus this hypothesis is not the best account of the data. Nevertheless, we fit a model that enforces the absence of cognitive noise (i.e., with 𝜈 = 0). The BIC of this “motor-noise-only” model is higher than that of our best-fitting model by more than 1100, indicating very strong support for the best-fitting model, which features a positive cognitive noise (𝜈 > 0), and 𝛼 = 1/2, as in our theoretical proposal.
Furthermore, the standard deviation of responses predicted by the motor-noise-only model overestimates substantially the variability of subjects' responses in the Narrow and Medium conditions (Figure 4, panel b), while the predictions of the best-fitting model are much closer to the behavioral data (panel a). Finally, the variances predicted by this model do not increase linearly with the prior width (contrary to the behavioral data). Instead, the variance increases more between the Narrow and the Medium priors than between the Medium and the Wide priors, as the effects of the bounds attenuate with the wider prior (panel c, solid green line).
To further this analysis we fit in addition a model with no cognitive noise (𝜈 = 0), but in which we now allow the degree of motor noise, 𝜎0, to depend on the prior. Our reasoning is that if the truncated motor noise were the sole explanation for the increase in subjects' variance with the prior width, then we would expect the noise levels for the three priors to be roughly equal. We find instead that they are different (with values of 5.9, 8.3, and 9.8, for the prior widths 20, 40, and 60, respectively, when pooling subjects; and when fitting subjects individually the distributions of parameter values exhibit a clear increase; see panels c and d above). This model moreover yields a BIC higher by more than 590 than our best-fitting model. We note in addition that these parameter values differ in such a way that they result in response variances that are a linear function of the prior width, as found in the behavioral data, although they overestimate the subjects' variances (panel c, dotted green line). This linear increase is directly predicted by our best-fitting model, which has one less parameter (2 vs. 3), and which moreover accurately predicts the variability of subjects across priors (panel c, pink line). Hence the data do not support a model with no cognitive noise and with only a constant, truncated motor noise.
We also consider another possibility, that in addition to truncated motor noise there is in fact a degree of cognitive noise, but one that is insensitive to the width of the prior. In other words, there is cognitive imprecision, but it does not efficiently adapt to the prior range, as in our proposal. This corresponds to setting 𝛼 = 0, in our model; but this specification of the model results in a poor fit, with a BIC higher by more than 300 than that of the best-fitting model, whose cognitive noise scales with the exponent 𝛼 = 1/2, consistent with our theory. Thus our data do not support the hypothesis of a cognitive noise that does not scale with the prior range; instead, subjects' responses support a model in which the variance of the cognitive noise increases linearly with the prior range.
We note in addition that there is inter-subject variability: different subjects have different degrees of imprecision. But if the source of the imprecision was the truncated motor noise, then different degrees of truncated noise should result in different relationships between the behavioral variance and the prior widths: subjects with smaller noise should be relatively insensitive to the width of the prior, while subjects with greater noise should be more sensitive. In that case, when fitting the subjects with the model in which the imprecision scales as a power of the width, we should expect subjects to exhibit a diversity of best-fitting parameter values 𝛼. Instead, as noted, we find that the data is best captured by a single exponent 𝛼 = 1/2, equal for all the subjects. This suggests that although the “baseline level” of the imprecision may differ per subject, the way that their imprecision increases as a function of the prior width is the same for all the subjects, a behavior that is not explained by truncated noise alone.
Furthermore, Prat-Carrabin, Harl, and Gershman 2025 present behavioral results obtained in a similar numerosity-estimation task, with the same prior ranges, but with the experimental difference that the slider was not limited to the range of the current prior: instead it had the same width in all three conditions, and covered in all trials a range wider than that of the Wide prior (from 25 to 95). The behavioral variance observed in this study increases linearly with the prior range, as in our results. Thus we conclude that the linear increase in subjects' variability does not originate in the bounds of the experimental slider.
Finally, Prat-Carrabin et al. 2025 presents an fMRI study involving a similar numerosityestimation experiment. This study shows that numerosity-sensitive neural populations in human parietal cortex adapt their tuning properties to the current numerical range, resulting in less precise neural encoding when the range is wider. This substantiates the notion that the degree of imprecision in cognitive noise adapts to the prior range, as in our proposal.
Overall, we conclude that the linear increase of behavioral variability that we document originates in the endogenous adaptation, across conditions, of the amount of imprecision in the internal encoding of numerosities.
We now include these analyses in a new section of the Methods (p. 24-27), which we summarize in the main text (p. 7-8). The Figure above is now included (as Figure 4). We also now cite the references mentioned by Reviewer #1 and which we had not already cited (Bhui and Gershman 2018 Psych Review; Hahn and Wei 2024 Nature Neuro).
References:
Prat-Carrabin, A., Harl, M. V., & Gershman, S. J. (2025). Fast efficient coding and sensory adaptation in gain-adaptive recurrent networks (p. 2025.07.11.664261). bioRxiv. https://doi.org/10.1101/2025.07.11.664261
Prat-Carrabin, A., de Hollander, G., Bedi, S., Gershman, S. J., & Ruff, C. C. (2025). Distributed range adaptation in human parietal encoding of numbers (p. 2025.09.25.675916). bioRxiv. https://doi.org/10.1101/2025.09.25.675916
(2) Differences across tasks
A main takeaway from the paper is that optimal coding depends on the expected reward function in each task. This is the explanation for why the degree of sublinearity between standard deviation and prior width changes across the estimation and discrimination task. But besides the two different reward functions, there are also other differences across the two tasks. For example, the estimation task involves a single array of dots, whereas the discrimination task involves a pair of sequences of Arabic numerals. Related to the discussion above, in the estimation task the response scale is continuous whereas in the discrimination task, responses are binary. Is it possible that these other differences in the task could contribute to the observed different degrees of sublinearity? It is likely beyond the scope of the paper to incorporate these differences into the model, but such differences across the two tasks should be discussed as potential drivers of differences in observed behavior.
If it becomes too difficult to interpret the data from the estimation task due to the slider bar varying with the prior range, then which of the paper's conclusions would still follow when restricting the analysis to the discrimination task?
There are indeed several differences between the estimation and discrimination tasks that could, in principle, contribute to the quantitative differences observed between them. The fact that the estimation task requires a continuous numerical report whereas the discrimination task involves a binary choice is captured in our model by incorporating distinct loss functions for the two tasks (Eq. 4). This distinction is a key element of the theoretical framework, as it determines the optimal allocation of representational precision. We agree with Reviewer #1 that another important difference is that the estimation task involves non-symbolic dot arrays while the discrimination task uses short sequences of Arabic numerals, which could also affect performance through distinct perceptual or cognitive processes. Although we cannot exclude this possibility, it is unclear why such a difference in stimulus format would produce the specific quantitative patterns that we observe — and that are predicted by our proposal, namely, the sublinear scalings with task-dependent exponents. Each experiment, taken independently, supports the model's central prediction that the precision of internal representations scales sublinearly with the width of the prior distribution. Taken together, the two tasks show that this dependence itself varies with the observer's objective, confirming that perceptual precision is endogenously determined by both the statistical context and the task goal.
We agree with Reviewer #1 that this point should be mentioned; we now do so in the Discussion (p. 17-18).
(3) Placement literature
One closely related experiment to the discrimination task in the current paper can be found in Frydman and Jin (2022 Quarterly Journal of Economics). Those authors also experimentally vary the width of a uniform prior in a discrimination task using Arabic numerals, in order to test principles of efficient coding. Consistent with the current findings, Frydman and Jin find that subjects exhibit greater precision when making judgments about numbers drawn from a narrower distribution. However, what the current manuscript does is it goes beyond Frydman and Jin by modeling and experimentally varying task objectives to understand and test the effects on optimal coding. This contribution should be highlighted and contrasted against the earlier experimental work of Frydman and Jin to better articulate the novelty of the current manuscript.
We thank Reviewer #1 and we agree that the work of Frydman and Jin is highly relevant to our study. Instead of comparing our contributions to theirs, we have decided to have a close look at their data, in light of our theoretical proposal. This enables us to test the predictions of our theory against human choices made in a rather different decision situation than that of our discrimination task.
Thus we looked, in their data, at the participants' probability of choosing the risky lottery instead of the certain amount, as a function of the difference between the lottery's expected value (pX) and the certain amount (C; we also added a small bias term to the certain option; such bias was not necessary with our discrimination data, presumably because of the inherent symmetry of our task).
We find, as did Frydman and Jin, and similarly to our discrimination task, that the participants are more precise when the proposed amounts are sampled from a Narrow prior, in comparison to a Wide prior (see figure above, first panel). But we also find, as in our discrimination task, that when normalizing the value difference by the prior width participants are more sensitive to this normalized difference in the Wide condition than in the Narrow one, suggesting that their imprecision scales across conditions by a smaller factor than the prior width (last panel). And we find, consistent with our discrimination data and with our theory, that choice probabilities in the two conditions match very well when normalizing the difference by the prior width raised to the exponent 3/4 (third panel).
Model fitting supports this observation. We fit the data to our model (described by Eq. 3), with the addition of a lapse probability and of a bias, and with different values of the exponent 𝛼. The best-fitting model is the one with 𝛼 = 3/4. Its BIC (35,419) is lower than those of the models with 𝛼 = 1, ½, and 0 (by 142, 39, and 514, respectively). It is also lower by 2.14 than a model in which 𝛼 is left as a free parameter (in which case the bestfitting 𝛼 is 0.68, a value not far from 3/4). We emphasize that these BIC values indicate that the hypotheses 𝛼 = 0 and 𝛼 =1 are clearly rejected, i.e., the participants' imprecision increases with the prior width (𝛼 > 0), but sublinearly (𝛼 < 1). In other words, the responses collected by Frydman and Jin in a risky-choice task are quantitatively consistent with our results obtained in a number-discrimination task, and they further substantiate our model of endogenous precision.
We moreover note that their proposed model is similar to ours, in that the decision-maker is allowed to optimize a noisy encoding scheme to the prior, subject to a ‘capacity constraint’ on the number 𝑛 of encoding signals that can be obtained. Crucially, this capacity constraint is assumed to be a property of the decision-maker that does not change across priors, and thus 𝑛 is fixed across prior widths. Therefore, their model predicts that the participants' imprecision should scale linearly with the prior width (this is also what we obtain in our model if we don’t optimize a similar parameter; see the revised presentation of the model on p. 12-13). We note that when they fit this parameter, 𝑛, separately across conditions, they find that it is larger with the wider prior. This is precisely what our model of endogenous precision predicts. In turn this predicts a sublinear scaling of the imprecision, instead of the linear one that would result from a fixed 𝑛, and indeed we find a sublinear scaling in both their dataset and ours. What is more, in both datasets the sublinear scaling is best captured by the exponent 𝛼 = 3/4, as we predict.
This analysis of another independent dataset obtained with a different experimental paradigm significantly strengthens our conclusions. Thus we added to the Results section a new subsection discussing this analysis, and the figure above now appears as Figure 3. We also mention it in the Introduction (l. 87-89) and in the Discussion (l. 556-557).
Reviewer #2 (Public review):
Summary:
This paper provides an ingenious experimental test of an efficient coding objective based on optimization as a task success. The key idea is that different tasks (estimation vs discrimination) will, under the proposed model, lead to a different scaling between the encoding precision and the width of the prior distribution. Empirical evidence in two tasks involving number perception supports this idea.
Strengths:
The paper provides an elegant test of a prediction made by a certain class of efficient coding models previously investigated theoretically by the authors.
The results in experiments and modeling suggest that competing efficient coding models, optimizing mutual information alone, may be incomplete by missing the role of the task.
We thank Reviewer #2 for her/his positive comments on our work.
Weaknesses:
The claims would be more strongly validated if data were present at more than two widths in the discrimination experiment.
We agree that including additional prior widths would allow for a more detailed validation of the predicted scaling law, in particular in the discrimination task. Our design choices across the two experiments reflect a trade-off between the number of prior widths and the number of trials per condition. In the estimation task, we include three widths because this is necessary to identify all three parameters of the model: the variance of the motor noise
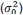 , the baseline variance of internal imprecision (𝜈2), and the scaling exponent (𝛼). Extending both tasks to include additional prior widths would indeed provide a more robust test of the predicted scaling law. We now note this point in the revised Discussion (p. 17).
, the baseline variance of internal imprecision (𝜈2), and the scaling exponent (𝛼). Extending both tasks to include additional prior widths would indeed provide a more robust test of the predicted scaling law. We now note this point in the revised Discussion (p. 17).A very strong prediction of the model -- which determines encoding entirely from prior and task -- is that Fisher Information is uniform throughout the range, strongly at odds with the traditional assumption of imprecision increasing with the numerosity (Weber/Fechner law). This prediction should be checked against the data collected. It may not be trivial to determine this in the Estimation experiment, but should be feasible in the Discrimination experiment in the Wide condition: Is there really no difference in discriminability at numbers close to 10 vs numbers close to 90? Figure 2 collapses over those, so it's not evident whether such a difference holds or not. I'd have loved to look into this in reviewing, but the authors have not yet made their data publicly available - I strongly encourage them to do so.
Importantly, the inverse u-shaped pattern in Figure 1 is itself compatible with a Weber's-law-based encoding, as shown by simulation in Figure 5d in Hahn&Wei [1]. This suggests a potential competing variant account, in apparent qualitative agreement with the findings reported: the encoding is compatible with Fisher's law, and only a single scalar, the magnitude of sensory noise, is optimized for the task for the loss function (3). As this account would be substantially more in line with traditional accounts of numerosity perception - while still exhibiting taskdependence of encoding as proposed by the authors - it would be worth investigating if it can be ruled out based on the data gathered for this paper.
References:
[1] Hahn & Wei, A unifying theory explains seemingly contradictory biases in perceptual estimation, Nature Neuroscience 2024
Indeed our efficient-coding model predicts that a uniform should result in a constant Fisher-information function, and we agree with Reviewer #2 that this is at odds with the common assumption that the imprecision increases with the magnitude. To investigate this possibility, we now consider, in the revised manuscript, a more general model of Gaussian encoding, in which the internal representation, 𝑟, is normally distributed around an increasing transformation of the number, 𝜇(𝑥), as
𝑟|𝑥~𝑁(𝜇(𝑥), 𝜈2𝑤2 𝛼),
where the encoding function, 𝜇(𝑥), can be either linear (𝜇(𝑥) = 𝑥) or logarithmic (𝜇(𝑥) = log (𝑥)). This allows us to test whether the data are better captured by a uniform Fisher information (as predicted by the linear encoding under a uniform prior) or by a compressed, Weber-like representation.
We note, first, that in both tasks our conclusions regarding the dependence of the imprecision on the prior width remain unchanged, whether we choose the linear encoding or the logarithmic encoding. With both choice of encoding, the estimation task is best fit by a model with 𝛼 = 1/2, and the discrimination task by a model with 𝛼 = 3/4, implying a sublinear scaling of the variance with the width of the prior, in quantitative agreement with our theory.
In the estimation task, the logarithmic encoding yields a significantly lower BIC than the linear one, by more than 380 (see Table 1). The results are less clear in the discrimination task, where the BIC with the logarithmic encoding is lower by 2.1 when pooling together the responses of all the subject, but it is larger by 2.6 when fitting each subject individually. We conduct in addition a “Bayesian model selection” procedure, to estimate the relative prevalence of each encoding among subjects. The resulting estimate of the fraction of the population that is best fit by the logarithmic encoding is 87.6% in the estimation task, and 45.9% in the discrimination task (vs. 12.4% and 54.1% for the linear encoding).
To further investigate the behavior of subject in the Discrimination task, we look at their proportion of correct choices in the Wide and Narrow conditions, for the trials in which both averages are below the middle value of the prior, and for those in which both are above the middle value. We find no significant difference in the Narrow condition (see Figure below). In the Wide condition, the proportion of correct responses appear larger when the averages are small (with a significant difference when binning together the trials in which the absolute difference between the averages is between 4 and 12; Fisher's exact test p-value: 0.030).
To complement this analysis, we fit a probit model with lapses, which is equivalent to our Gaussian model with linear encoding, but allowing the noise scale parameter to differ when both averages are above, or below, the middle value of the prior. We fit this model separately in each condition, only on the trials in which both averages are either above or below the middle value; and we test a more constrained model in which the scale parameter is equal for both small and large averages. In the Narrow condition, a likelihood-ratio test does not reject the null hypothesis that the scale parameter is constant (𝜒2(1) = 0.026, 𝑝 = 0.87), but in the Wide condition this hypothesis is rejected (𝜒2 (1) = 7.6, 𝑝 = 0.006). In this condition the best-fitting scale parameter is 29% larger (9.4 vs. 6.3) with the large averages than with the small averages, pointing to a larger imprecision with the larger numbers.
These results and the prevalence of the Weber/Fechner encoding prompt us to consider, in our efficient-coding model, the hypothesis that a logarithmic compression is an additional constraint on the possible encoding schemes. In our model, the internal representation (𝑟) could take any form as long as its Fisher information verified the constraint in Eq. 5 on the integral of its square-root. We now consider a strong, additional constraint: that over the support of the prior, the Fisher information of the signal must be of the form that one would obtain with a logarithmic encoding, i.e., 𝐼(𝑥) ∝ 1/𝑥2. (For the sake of generality we choose this specification instead of directly assuming a logarithmic encoding, because other types of encoding schemes yield a Fisher information of this form, e.g., one with “multiplicative noise” (Zhou et al., 2024); we do not seek, here, to distinguish between these different possibilities). We solve the same efficient-coding optimization problem (Eq. 6), but now with this additional constraint. We find that the resulting optimal Fisher information is approximately:
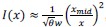 , for the estimation task,
, for the estimation task,and
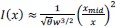 , for the discrimination task,
, for the discrimination task,for any 𝑥 on the support of the prior, and where 𝑥mid is the middle of the prior and 𝜃 is a constant. These Fisher-information functions differ from the one previously obtained without the additional constraint (Eq. 9), in that they fall off as 1/𝑥2, consistent with our additional constraint. However, we note that the dependence on the prior width, 𝑤, is identical: here also, the imprecision
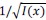 is proportional to
is proportional to 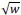 , in the estimation task, and to 𝑤3/4, in the discrimination task.
, in the estimation task, and to 𝑤3/4, in the discrimination task.In its logarithmic variant (𝜇(𝑥) = log (𝑥)), the Fisher information of the model of Gaussian representations that we have considered throughout is 1/(𝑥 𝜈 𝑤𝛼)2. It is thus consistent with the predictions just presented, if 𝛼 = 1/2 for the estimation task, and 𝛼 = 3/4 for the discrimination task, i.e., the two values that best fit the data.
This is precisely the model suggested by Reviewer #2. Overall, we conclude that with both linear and logarithmic encoding schemes, our efficient-coding model — wherein the degree of imprecision is endogenously determined — accounts for the task-dependent sublinear scaling of the imprecision that we observe in behavioral data. As for the imprecision across numbers, a sizable fraction of subjects, particularly in the estimation task, are best fit by the logarithmic encoding, consistent with previous reports that numbers are often represented on a compressed, approximately logarithmic scale. This encoding may itself reflect an efficient adaptation to a long-term environmental prior that is skewed, with smaller numbers occurring more frequently, leading to greater representational precision. This pattern is less clear in the discrimination task. It is possible that the rate at which the precision decreases across numbers itself depends on the task, such that not only the overall level of imprecision, but also its variation across numbers, may be modulated by the task's demands. In this study we have focused on the endogenous choice of the overall precision, but an avenue for future research would be to examine how this adaptation interacts with the detailed shape of the encoding across numbers.
In the revised manuscript, we have modified the presentation of the model to include the transformation 𝜇(𝑥) (p. 6-7 and 10-11). We have updated accordingly Table 1 (shown above; p. 24), which reports the BICs of all the models for the estimation task (and which now includes the models with logarithmic encoding). There is now a section in the Results dedicated to the question of the logarithmic compression, which includes the efficientcoding model constrained by the logarithmic encoding (p. 15-16). The results on the performance of subjects with larger numbers are presented in Methods (p. 29-31), and mentioned in the main text (p. 14-15). The Methods also provides details about the efficient-coding model with logarithmic encoding (p. 32-33). These results are further commented on in the Discussion (p. 18). Finally, the data and code are now available online at this address: https://osf.io/d6k3m/ , which we note on p. 33.
Reference
Zhou, J., Duong, L. R., & Simoncelli, E. P. (2024). A unified framework for perceived magnitude and discriminability of sensory stimuli. Proceedings of the National Academy of Sciences, 121(25), e2312293121. https://doi.org/10.1073/pnas.2312293121
Reviewer #3 (Public review):
Summary:
This work demonstrates that people's imprecision in numeric perception varies with the stimulus context and task goal. By measuring imprecision across different widths of uniform prior distributions in estimation and discrimination tasks, the authors find that imprecision changes sublinearly with prior width, challenging previous range normalization models. They further show that these changes align with the efficient encoding model, where decision-makers balance expected rewards and encoding costs optimally.
Strengths:
The experimental design is straightforward, controlling the mean of the number distribution while varying the prior width. By assessing estimation errors and discrimination accuracy, the authors effectively highlight how imprecision adjusts across conditions.
The model's predictions align well with the data, with the exponential terms (1/2 and 3/4) of imprecision changes matching the empirical results impressively.
We thank Reviewer #3 for his/her positive comments on our work.
Weaknesses:
Some details in the model section are unclear. Specifically, I'm puzzled by the Wiener process assumption where r∣x∼N(m(x)T,s^2T). Does this imply that both the representation of number x and the noise are nearly zero at the beginning, increasing as observation time progresses? This seems counterintuitive, and a clearer explanation would be helpful.
In the original formulation of the model, indeed both the mean of the representation and its variance are nearly zero when T is also near zero, but in such a way that the Fisher information, 𝑇(𝑚′(𝑥)/𝑠)2, is proportional to 𝑇. We note that a different specification, with a mean 𝑚(𝑥) (instead of 𝑚(𝑥)𝑇) and a variance 𝑠2/𝑇 (instead of 𝑠2𝑇), i.e., 𝑟|𝑥~𝑁(𝑚(𝑥), 𝑠2/𝑇), for 𝑇 > 0, would result in the same Fisher information.
In any event, in the revised manuscript, we now formulate the model differently. Specifically, we assume that the encoding results from an accumulation of independent, identically-distributed signals, but the precision of each signal is limited, and each of them entails a cost. Formally, we posit, first, that the Fisher information of one signal, 𝐼1(𝑥), is subject to the constraint:
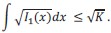
This constraint appears in many other efficient-coding models in the literature (Wei & Stocker 2015, 2016; Wang et al. 2016; Morais & Pillow, 2018; etc.), and it arises naturally for unidimensional encoding channels (Prat-Carrabin & Woodford, 2001; e.g., for a neuron with a sigmoidal tuning curve, it is equivalent to assuming that the range of possible firing rates is bounded). Second, we assume that the observer incurs a cost each time a signal is emitted (e.g., the energy resources consumed by action potentials). The total cost is thus proportional to the number of signals, which we denote by 𝑛. More signals, however, allow for a better precision: specifically, under the assumption of independent signals, the total Fisher information resulting from 𝑛 signals is the sum of the Fisher information of each signal, i.e., 𝐼(𝑥) = 𝑛𝐼1(𝑥).
A tradeoff ensues between the increased precision brought by accumulating more signals, and the cost of these signals. We assume that the observer chooses the function 𝐼1(.) and the number 𝑛 of signals that solve the minimization problem
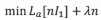 subject to
subject to 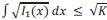 ,
,where 𝜆 > 0. We can first solve this problem for the Fisher information of one signal, 𝐼1(𝑥). In the case of a uniform prior of width 𝑤, we find that it is zero outside of the support of the prior, and
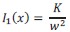
for any 𝑥 on the support of the prior. This intermediate result corresponds to the optimal Fisher information of an observer who is not allowed to choose the number of signal, 𝑛, (and who receives instead 𝑛 = 1 signal). It is the solution predicted by the efficient-coding models mentioned above, that include the constraint on 𝐼1(𝑥), but that do not allow for the observer to choose the amount of signals, 𝑛. With this solution, the scale of the observer's imprecision,
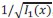 , is proportional to 𝑤, and it does not depend on the task — contrary to our experimental results.
, is proportional to 𝑤, and it does not depend on the task — contrary to our experimental results.Solving the optimization problem for 𝑛, in addition to 𝐼1(𝑥), we find that with a uniform prior the optimal number is proportional to 𝑤 in the estimation task, and to
in the discrimination task (specifically, treating 𝑛 as continuous, we obtain 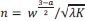 ). In other words, the observer chooses to obtain more signals when the prior is wider, and in a way that depends on the task. We give the general solution for the total Fisher information, 𝐼(𝑥) = 𝑛𝐼1(𝑥), in the case of a prior 𝜋(𝑥) that is not necessarily uniform:
). In other words, the observer chooses to obtain more signals when the prior is wider, and in a way that depends on the task. We give the general solution for the total Fisher information, 𝐼(𝑥) = 𝑛𝐼1(𝑥), in the case of a prior 𝜋(𝑥) that is not necessarily uniform: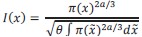
where 𝜃 = 𝜆/𝐾. This is of course the same solution that we obtained in the original manuscript.
We hope that this new formulation of the efficient-coding model will seem more intuitive to the reader (p. 12-13 in the revised manuscript).
The authors explore range normalization models with Gaussian representation, but another common approach is the logarithmic representation (Barretto-García et al., 2023; Khaw et al., 2021). Could the logarithmic representation similarly lead to sublinearity in noise and distribution width?
We agree with Reviewer #3 that a common approach when modeling the perception of numbers is to consider a logarithmic encoding. We have conducted several analyzes that examine this proposal. These are presented in detail in our response to a comment of Reviewer #2, above (p. 11-14 of this document). We summarize shortly our findings, here:
(i) A model with a logarithmic encoding better fits a majority of subjects in the estimation task, but a bit less than half the subjects in the discrimination task.
(ii) The examination of the performance of subjects in the discrimination task, however, suggests that in the Wide condition they discriminate slightly better the small numbers, as compared to the larger numbers.
(iii) We consider a constrained version of our efficient-coding model, in which the Fisher information must be consistent with that of a logarithmic encoding (i.e., decreasing as 1/𝑥2); we find that the resulting optimal Fisher information depends on the prior width in the same way than without the constraint, i.e., a scaling of the imprecision with
, in the estimation task, and with 𝑤3/4, in the discrimination task.(iv) When considering the model with logarithmic encoding, we find that it best fits the data when its imprecision scales with the width with the same exponents, i.e.,
, in the estimation task (𝛼 = 1/2), and 𝑤3/4, in the discrimination task (𝛼 = 3/4). In other words, the data support the predictions of our theoretical model.In the revised manuscript, we have modified accordingly the presentation of the model (p. 6-7 and 10-11), the Tables 1 (p. 24) and 2 (p. 30) which report the BICs. There is now a section in the Results dedicated to the question of the logarithmic compression, including the efficient-coding model constrained by the logarithmic encoding (p. 15-16). The results on the performance of subjects with larger numbers are presented in Methods (p. 29-31), and mentioned in the main text (p. 15-16). The Methods also provides details about the efficient-coding model with logarithmic encoding (p. 32-33). These results are further commented on in the Discussion (p. 18). Finally, we now cite the articles mentioned by Reviewer #3 (Barretto-García et al., 2023; Khaw et al., 2021).
Additionally, Heng et al. (2020) found that subjects did not alter their encoding strategy across different task goals, which seems inconsistent with the fully adaptive representation proposed here. I didn't find the analysis of participants' temporal dynamics of adaptation. The behavioral results in the manuscript seem to imply that the subjects adopted different coding schemes in a very short period of time. Yet in previous studies of adaptation, experimental results seem to be more supportive of a partial adaptive behavior (Bujold et al., 2021; Heng et al., 2020), which might balance experimental and real-world prior distributions. Analyzing temporal dynamics might provide more insight. Noting that the authors informed subjects about the shape of the prior distribution before the experiment, do the results in this manuscript suggest a top-down rapid modulation of number representation?
We thank Reviewer #3 for his/her comment and for pointing to these articles. The Reviewer raises several points — that of the dynamics of adaptation, that of the adaptation to the prior, and that of the adaptation to the task. We address each of them.
To investigate the dynamics of the subjects’ adaptation, we examined separately, in each task, the responses obtained in the trials in the first and second halves of each condition. In the estimation task, the standard deviations of responses, as a function of the presented number and of the prior width, are very similar in the two halves (see Figure 8, panel a). The Bonferroni-Holm-corrected p-values of Levene's tests of equality of the variances across the two halves are all above 0.13, and thus we do not reject the hypothesis that the variance in the first half of the trials is equal to the variance in the second half. Moreover, the variance in both halves appear to be a linear function of the width, rather than the squared width (panel b). We conclude that the behavior of subjects in the estimation task is stable across each experimental condition, including the sublinear scaling of their imprecision.
In the discrimination task, the subjects' choice probabilities, as a function of the difference between the averages of the red and blue numbers, are similar in the first and second halves of trials (panel c). The Bonferroni-Holm-corrected p-values of Fisher exact tests of equality of proportions (in bins of the average difference that contain about 500 trials each) are all above 0.9, and thus we do not reject the hypothesis that the choice probabilities are equal, in the first and second halves of the trials. Furthermore, the choice probabilities as a function of the absolute average difference normalized by the prior width raised to the exponent 3/4 are all similar, across session halves and across prior widths, suggesting that the sublinear scaling that we find is a stable behavior of subjects (panel d).
Overall, we conclude that the behavior we exhibit in both tasks is stable over the course of each experimental condition. We note that in both experiments, subjects were explicitly informed of the prior distribution at the beginning of each condition, and each condition included two preliminary training phases that familiarized them with the prior (the specifics for each task are detailed in the Methods section).
As pointed out by Reviewer #3, Heng et al. (2020) and Bujold et al. (2021) report a partial adaptation of encoding to recently experienced distributions. We note that in our study, a sizable fraction of subjects, particularly in the estimation task, are best fit by the logarithmic encoding. This suggests that, while subjects adapt to the experimental prior, they retain a residual logarithmic compression — an encoding that itself would be efficient under a long-term, skewed prior in which smaller numbers are more frequent. In that sense our findings are thus consistent with the partial adaptation of Heng et al. (2020) and Bujold et al. (2021). At the same time, the same sublinear scaling of imprecision that we find in our study has been obtained in a numerosity-estimation task in which the prior was changed on every trial (Prat-Carrabin et al., 2025), indicating that the adaptation to the prior can occur quickly (on the order of a second) — possibly through a fast top-down modulation of the encoding, as suggested by Reviewer #3. These findings suggest that on a short timescale the encoding adapts efficiently to the prior (as evidenced by the scaling in imprecision), but within structural constraints (the logarithmic encoding).
Regarding the adaptation to the task, Heng et al. (2020) indeed do not find subjects to be adapting their encoding, across two discrimination tasks (one in which the subject is rewarded for making the correct choice, and one in which the subject is rewarded with the chosen option). A difference with our paradigm is that their task involves simultaneous presentation of two dot arrays, while our discrimination task uses two interleaved sequences of Arabic numerals. More importantly, we do not directly compare the encoding between the estimation and discrimination tasks. Instead, we show that within each task, the adaptation to the prior is quantitatively consistent with the optimal coding predicted for that task's objective, as reflected in the task-specific sublinear scaling exponents. Directly contrasting the encoding across tasks would be a very interesting direction for future work.
In the revised manuscript, we present the analysis on the stability of subjects’ behavior in the Methods section (p. 29), and we mention it in the main text when presenting the results of the estimation task (p. 5) and of the discrimination task (p. 8-10). In the Discussion, we cite Heng et al. (2020) and Bujold et al. (2021) and comment on the adaptation to the prior and to the task (p. 18).
Barretto-García, M., De Hollander, G., Grueschow, M., Polanía, R., Woodford, M., & Ruff, C. C. (2023). Individual risk attitudes arise from noise in neurocognitive magnitude representations. Nature Human Behaviour, 7(9), 15511567. https://doi.org/10.1038/s41562-023-01643-4
Bujold, P. M., Ferrari-Toniolo, S., & Schultz, W. (2021). Adaptation of utility functions to reward distribution in rhesus monkeys. Cognition, 214, 104764. https://doi.org/10.1016/j.cognition.2021.104764
Heng, J. A., Woodford, M., & Polania, R. (2020). Efficient sampling and noisy decisions. eLife, 9, e54962. https://doi.org/10.7554/eLife.54962
Khaw, M. W., Li, Z., & Woodford, M. (2021). Cognitive Imprecision and SmallStakes Risk Aversion. The Review of Economic Studies, 88(4), 19792013. https://doi.org/10.1093/restud/rdaa044
Recommendations for the authors:
Reviewer #2 (Recommendations for the authors):
(1) As mentioned above, the result of inverse u-shaped variability is in strong qualitative agreement with the predictions of a generic Bayesian encoding-decoding model of a flat prior, even under a standard encoding respecting Weber's law, as shown in Figure 5d in: Hahn & Wei, A unifying theory explains seemingly contradictory biases in perceptual estimation, Nature Neuroscience 2024. This paper should probably be cited.
We now cite Hahn & Wei, 2024. We comment above on our analyzes regarding the logarithmic encoding.
(2) "Requests for the data can be sent via email to the corresponding author" Why are the data not made openly available? Barring ethical or legal concerns (which are not apparent for this type of data), there is no reason not to make data and code open.
"Requests for the code used for all analyses can be sent via email to the corresponding author." Same: why not make them open?
We agree that it is good practice to make the data and code publicly available. They are now available here: https://osf.io/d6k3m/
Reviewer #3 (Recommendations for the authors):
The orange dot in Figure 1C does not appear to be described in the figure caption, although an explanation of it is mentioned in the main text.
We thank Reviewer #3 for pointing out this omission. We now include explanations in the caption.
I hope the authors will consider making their data publicly available on OSF or another platform.
The data and code are now publicly available on OSF: https://osf.io/d6k3m/
-
-
eLife assessment
This research investigates the precision of numerosity perception in two different tasks and concludes that human performance aligns with an efficient coding model optimized for current environmental statistics and task goals. The findings may have important implications for our understanding of numerosity perception as well as the ongoing debate on different efficient coding models. However, the evidence presented in the paper to support the conclusion is still incomplete and could be strengthened by further modeling analysis or experimental data that can address potential confounds.
-
Reviewer #1 (Public review):
Summary:
The "number sense" refers to an imprecise and noisy representation of number. Many researchers propose that the number sense confers a fixed (exogenous) subjective representation of number that adheres to scalar variability, whereby the variance of the representation of number is linear in the number.
This manuscript investigates whether the representation of number is fixed, as usually assumed in the literature, or whether it is endogenous. The two dimensions on which the authors investigate this endogeneity are the subject's prior beliefs about stimuli values and the task objective. Using two experimental tasks, the authors collect data that are shown to violate scalar variability and are instead consistent with a model of optimal encoding and decoding, where the encoding phase depends …
Reviewer #1 (Public review):
Summary:
The "number sense" refers to an imprecise and noisy representation of number. Many researchers propose that the number sense confers a fixed (exogenous) subjective representation of number that adheres to scalar variability, whereby the variance of the representation of number is linear in the number.
This manuscript investigates whether the representation of number is fixed, as usually assumed in the literature, or whether it is endogenous. The two dimensions on which the authors investigate this endogeneity are the subject's prior beliefs about stimuli values and the task objective. Using two experimental tasks, the authors collect data that are shown to violate scalar variability and are instead consistent with a model of optimal encoding and decoding, where the encoding phase depends endogenously on prior and task objectives. I believe the paper asks a critically important question. The literature in cognitive science, psychology, and increasingly in economics, has provided growing empirical evidence of decision-making consistent with efficient coding. However, the precise model mechanics can differ substantially across studies. This point was made forcefully in a paper by Ma and Woodford (2020, Behavioral & Brain Sciences), who argue that different researchers make different assumptions about the objective function and resource constraints across efficient coding models, leading to a proliferation of different models with ad-hoc assumptions. Thus, the possibility that optimal coding depends endogenously on the prior and the objective of the task, opens the door to a more parsimonious framework in which assumptions of the model can be constrained by environmental features. Along these lines, one of the authors' conclusions is that the degree of variability in subjective responses increases sublinearly in the width of the prior. And importantly, the degree of this sublinearity differs across the two tasks, in a manner that is consistent with a unified efficient coding model.
Comments:
(1) Modeling and implementation of estimation task
The biggest concern I have with the paper is about the experimental implementation and theoretical account of the estimation task. The salient features of the experimental data (Figure 1C) are that the standard deviations of subjects' estimated quantities are hump-shaped in the true stimulus x and that the standard deviation, conditional on the true stimulus x, is increasing in prior width. The authors attribute these features to a Bayesian encoding and decoding model in which the internal representation of the quantity is noisy, and the degree of noise depends on the prior - as in models of efficient coding (Wei and Stocker 2015 Nature Neuro; Bhui and Gershman 2018 Psych Review; Hahn and Wei 2024 Nature Neuro).
The concern I have is about the final "step" in the model, where the authors assume there is an additional layer of motor noise in selecting the response. The authors posit that the subject's selection of the response is drawn from a Gaussian with a mean set to the optimally decoded estimate x*(r), and variance set to a free parameter sigma_0^2. However, the authors also assume that the Gaussian distribution is "truncated to the prior range." This truncation is a nontrivial assumption, and I believe that on its own, it can explain many features of the data.
To see this, assume that there is no noise in the internal representation of x, there is only motor noise. This corresponds to a special case of the authors' model in which υ is set to 0. The model then reduces to a simple account in which responses are drawn from a Gaussian distribution centered at the true value of x, but with asymmetric noise due to the truncation. I simulated such a model with sigma_0=7. The resulting standard deviations of responses for each value of x (based on 1000 draws for each value of x), across the three different priors, reproduce the salient patterns of the standard deviation in Figure 1C: i) within each condition, the standard deviation is hump-shaped and peaks at x=60 and ii) conditional on x, standard deviation increases in prior width. The takeaway is that this simple model with only truncated motor noise - and without any noisy or efficient coding of internal representations - provides an alternative channel through which the prior affects behavior.
Of course, this does not imply that subjects' coding is not described by the efficient encoding and decoding model posited by the authors. However, it does suggest an important alternative mechanism for the authors' theoretical results in the estimation task. Moreover, some of the quantitative conclusions about the differences in behavior with the discrimination task would be greatly affected by the assumption of truncated motor noise.
Turning to the experiment, a basic question is whether such a truncation was actually implemented in the design. That is, was the range of the slider bar set to the range of the prior? (The methods section states that the size on the screen of the slider was proportional to the prior width, but it was unclear whether the bounds of the slider bar changed with the prior). If the slider bar range did depend on the prior, then it becomes difficult to interpret the data. If not, then perhaps one can perform analyses to understand how much the motor noise is responsible for the dependence of the standard deviation on both x and the prior width. Indeed, the authors emphasize that their model is best fit at α=0.48, which would seem to imply that the best fitting value of υ is strictly positive. However, it would be important to clarify whether the estimation procedure allowed for υ=0, or whether this noise parameter was constrained to be positive (i.e., clarify whether the estimation assumed noisy and efficient coding of internal representations).
(2) Differences across tasks
A main takeaway from the paper is that optimal coding depends on the expected reward function in each task. This is the explanation for why the degree of sublinearity between standard deviation and prior width changes across the estimation and discrimination task. But besides the two different reward functions, there are also other differences across the two tasks. For example, the estimation task involves a single array of dots, whereas the discrimination task involves a pair of sequences of Arabic numerals. Related to the discussion above, in the estimation task the response scale is continuous whereas in the discrimination task, responses are binary. Is it possible that these other differences in the task could contribute to the observed different degrees of sublinearity? It is likely beyond the scope of the paper to incorporate these differences into the model, but such differences across the two tasks should be discussed as potential drivers of differences in observed behavior.
If it becomes too difficult to interpret the data from the estimation task due to the slider bar varying with the prior range, then which of the paper's conclusions would still follow when restricting the analysis to the discrimination task?
(3) Placement literature
One closely related experiment to the discrimination task in the current paper can be found in Frydman and Jin (2022 Quarterly Journal of Economics). Those authors also experimentally vary the width of a uniform prior in a discrimination task using Arabic numerals, in order to test principles of efficient coding. Consistent with the current findings, Frydman and Jin find that subjects exhibit greater precision when making judgments about numbers drawn from a narrower distribution. However, what the current manuscript does is it goes beyond Frydman and Jin by modeling and experimentally varying task objectives to understand and test the effects on optimal coding. This contribution should be highlighted and contrasted against the earlier experimental work of Frydman and Jin to better articulate the novelty of the current manuscript.
-
Reviewer #2 (Public review):
Summary:
This paper provides an ingenious experimental test of an efficient coding objective based on optimization as a task success. The key idea is that different tasks (estimation vs discrimination) will, under the proposed model, lead to a different scaling between the encoding precision and the width of the prior distribution. Empirical evidence in two tasks involving number perception supports this idea.
Strengths:
- The paper provides an elegant test of a prediction made by a certain class of efficient coding models previously investigated theoretically by the authors.
The results in experiments and modeling suggest that competing efficient coding models, optimizing mutual information alone, may be incomplete by missing the role of the task.
Weaknesses:
- The claims would be more strongly validated if …
Reviewer #2 (Public review):
Summary:
This paper provides an ingenious experimental test of an efficient coding objective based on optimization as a task success. The key idea is that different tasks (estimation vs discrimination) will, under the proposed model, lead to a different scaling between the encoding precision and the width of the prior distribution. Empirical evidence in two tasks involving number perception supports this idea.
Strengths:
- The paper provides an elegant test of a prediction made by a certain class of efficient coding models previously investigated theoretically by the authors.
The results in experiments and modeling suggest that competing efficient coding models, optimizing mutual information alone, may be incomplete by missing the role of the task.
Weaknesses:
- The claims would be more strongly validated if data were present at more than two widths in the discrimination experiment.
- A very strong prediction of the model -- which determines encoding entirely from prior and task -- is that Fisher Information is uniform throughout the range, strongly at odds with the traditional assumption of imprecision increasing with the numerosity (Weber/Fechner law). This prediction should be checked against the data collected. It may not be trivial to determine this in the Estimation experiment, but should be feasible in the Discrimination experiment in the Wide condition: Is there really no difference in discriminability at numbers close to 10 vs numbers close to 90? Figure 2 collapses over those, so it's not evident whether such a difference holds or not. I'd have loved to look into this in reviewing, but the authors have not yet made their data publicly available - I strongly encourage them to do so.
Importantly, the inverse u-shaped pattern in Figure 1 is itself compatible with a Weber's-law-based encoding, as shown by simulation in Figure 5d in Hahn&Wei [1]. This suggests a potential competing variant account, in apparent qualitative agreement with the findings reported: the encoding is compatible with Fisher's law, and only a single scalar, the magnitude of sensory noise, is optimized for the task for the loss function (3). As this account would be substantially more in line with traditional accounts of numerosity perception - while still exhibiting task-dependence of encoding as proposed by the authors - it would be worth investigating if it can be ruled out based on the data gathered for this paper.
References:
[1] Hahn & Wei, A unifying theory explains seemingly contradictory biases in perceptual estimation, Nature Neuroscience 2024
-
Reviewer #3 (Public review):
Summary:
This work demonstrates that people's imprecision in numeric perception varies with the stimulus context and task goal. By measuring imprecision across different widths of uniform prior distributions in estimation and discrimination tasks, the authors find that imprecision changes sublinearly with prior width, challenging previous range normalization models. They further show that these changes align with the efficient encoding model, where decision-makers balance expected rewards and encoding costs optimally.
Strengths:
The experimental design is straightforward, controlling the mean of the number distribution while varying the prior width. By assessing estimation errors and discrimination accuracy, the authors effectively highlight how imprecision adjusts across conditions.
The model's predictions …
Reviewer #3 (Public review):
Summary:
This work demonstrates that people's imprecision in numeric perception varies with the stimulus context and task goal. By measuring imprecision across different widths of uniform prior distributions in estimation and discrimination tasks, the authors find that imprecision changes sublinearly with prior width, challenging previous range normalization models. They further show that these changes align with the efficient encoding model, where decision-makers balance expected rewards and encoding costs optimally.
Strengths:
The experimental design is straightforward, controlling the mean of the number distribution while varying the prior width. By assessing estimation errors and discrimination accuracy, the authors effectively highlight how imprecision adjusts across conditions.
The model's predictions align well with the data, with the exponential terms (1/2 and 3/4) of imprecision changes matching the empirical results impressively.
Weaknesses:
Some details in the model section are unclear. Specifically, I'm puzzled by the Wiener process assumption where r∣x∼N(m(x)T,s^2T). Does this imply that both the representation of number x and the noise are nearly zero at the beginning, increasing as observation time progresses? This seems counterintuitive, and a clearer explanation would be helpful.
The authors explore range normalization models with Gaussian representation, but another common approach is the logarithmic representation (Barretto-García et al., 2023; Khaw et al., 2021). Could the logarithmic representation similarly lead to sublinearity in noise and distribution width?
Additionally, Heng et al. (2020) found that subjects did not alter their encoding strategy across different task goals, which seems inconsistent with the fully adaptive representation proposed here. I didn't find the analysis of participants' temporal dynamics of adaptation. The behavioral results in the manuscript seem to imply that the subjects adopted different coding schemes in a very short period of time. Yet in previous studies of adaptation, experimental results seem to be more supportive of a partial adaptive behavior (Bujold et al., 2021; Heng et al., 2020), which might balance experimental and real-world prior distributions. Analyzing temporal dynamics might provide more insight. Noting that the authors informed subjects about the shape of the prior distribution before the experiment, do the results in this manuscript suggest a top-down rapid modulation of number representation?
Barretto-García, M., De Hollander, G., Grueschow, M., Polanía, R., Woodford, M., & Ruff, C. C. (2023). Individual risk attitudes arise from noise in neurocognitive magnitude representations. Nature Human Behaviour, 7(9), 1551-1567. https://doi.org/10.1038/s41562-023-01643-4
Bujold, P. M., Ferrari-Toniolo, S., & Schultz, W. (2021). Adaptation of utility functions to reward distribution in rhesus monkeys. Cognition, 214, 104764. https://doi.org/10.1016/j.cognition.2021.104764
Heng, J. A., Woodford, M., & Polania, R. (2020). Efficient sampling and noisy decisions. eLife, 9, e54962. https://doi.org/10.7554/eLife.54962
Khaw, M. W., Li, Z., & Woodford, M. (2021). Cognitive Imprecision and Small-Stakes Risk Aversion. The Review of Economic Studies, 88(4), 1979-2013. https://doi.org/10.1093/restud/rdaa044
-
