Brain-imaging evidence for compression of binary sound sequences in human memory
Curation statements for this article:-
Curated by eLife

eLife assessment
This article brings to bear a useful, extensive set of behavioral methods and neural data to report that activity in numerous cortical regions robustly covaries with the complexity of tone sequences encoded in memory. In its current state, the findings are solid but deserve further analysis to arrive at more convincing conclusions.
This article has been Reviewed by the following groups
Discuss this preprint
Start a discussion What are Sciety discussions?Listed in
- Evaluated articles (eLife)
Abstract
According to the language-of-thought hypothesis, regular sequences are compressed in human memory using recursive loops akin to a mental program that predicts future items. We tested this theory by probing memory for 16-item sequences made of two sounds. We recorded brain activity with functional MRI and magneto-encephalography (MEG) while participants listened to a hierarchy of sequences of variable complexity, whose minimal description required transition probabilities, chunking, or nested structures. Occasional deviant sounds probed the participants’ knowledge of the sequence. We predicted that task difficulty and brain activity would be proportional to the complexity derived from the minimal description length in our formal language. Furthermore, activity should increase with complexity for learned sequences, and decrease with complexity for deviants. These predictions were upheld in both fMRI and MEG, indicating that sequence predictions are highly dependent on sequence structure and become weaker and delayed as complexity increases. The proposed language recruited bilateral superior temporal, precentral, anterior intraparietal, and cerebellar cortices. These regions overlapped extensively with a localizer for mathematical calculation, and much less with spoken or written language processing. We propose that these areas collectively encode regular sequences as repetitions with variations and their recursive composition into nested structures.
Article activity feed
-

-

Author Response
Reviewer #1 (Public Review):
The manuscript investigates how humans store temporal sequences of tones in working memory. The authors mainly focus on a theory named "Language of thought" (LoT). Here the structure of a stimulus sequence can be stored in a tree structure that integrates the dependencies of a stimulus stored in working memory. To investigate the LoT hypothesis, participants listened to multiple stimulus sequences that varied in complexity (e.g., alternating tones vs. nearly random sequence). Simultaneously, the authors collected fMRI or MEG data to investigate the neuronal correlates of LoT complexity in working memory. Critical analysis was based on a deviant tone that violated the stored sequence structure. Deviant detection behavior and a bracketing task allowed a behavioral analysis.
Results showed …
Author Response
Reviewer #1 (Public Review):
The manuscript investigates how humans store temporal sequences of tones in working memory. The authors mainly focus on a theory named "Language of thought" (LoT). Here the structure of a stimulus sequence can be stored in a tree structure that integrates the dependencies of a stimulus stored in working memory. To investigate the LoT hypothesis, participants listened to multiple stimulus sequences that varied in complexity (e.g., alternating tones vs. nearly random sequence). Simultaneously, the authors collected fMRI or MEG data to investigate the neuronal correlates of LoT complexity in working memory. Critical analysis was based on a deviant tone that violated the stored sequence structure. Deviant detection behavior and a bracketing task allowed a behavioral analysis.
Results showed accurate bracketing and fast/correct responses when LoT complexity is low. fMRI data showed that LoT complexity correlated with the activation of 14 clusters. MEG data showed that LoT complexity correlated mainly with activation from 100-200 ms after stimulus onset. These and other analyses presented in the manuscript lead the authors to conclude that such tone sequences are represented in human memory using LoT in contrast to alternative representations that rely on distinct memory slot representations.
Strengths
The study provides a concise and easily accessible introduction. The task and stimuli are well described and allow a good understanding of what participants experience while their brain activation is recorded. Results are extensive as they include multiple behavioral investigations and brain activation data from two different measurement modalities. The presentation of the behavioral results is intuitive. The analysis provided a direct comparison of the LoT with an alternative model based on estimating a transition-probability measure of surprise.
For the fMRI data, the whole brain analysis was accompanied by detailed region of interest analyses, including time course analysis, for the activation clusters correlated with LoT complexity. In addition, the activation clusters have been set in relation (overlap and region of interest analyses) to a math and a language localizer. For the MEG data, the authors investigated the LoT complexity effect based on linear regression, including an analysis that also included transitional probabilities and multivariate decoding analysis. The discussion of the results focused on comparing the activation patterns of the task with the localizer tasks. Overall, the authors have provided considerable new data in multiple modalities on a well-designed experiment investigating how humans represent sequences in auditory working memory.
Weaknesses
The primary issue of the manuscript is the missing formal description of the LoT model and alternatives, inconsistencies in the model comparisons, and no clear argumentation that would allow the reader to understand the selection of the alternative model. Similar to a recent paper by similar authors (Planton et al., 2021 PLOS Computational Biology), an explicit model comparison analysis would allow a much stronger conclusion. Also, these analyses would provide a more extensive evidence base for the favored LoT model. Needed would be a clear argumentation for why the transitional probabilities were identified as the most optimal alternative model for a critical test. A clear description of the models (e.g., how many free parameters) and a description of the simulation procedure (e.g., are they trained, etc.) Here it would be strongly advised to provide the scripts that allow others to reproduce the simulations.
We thank the reviewer for the requests and critiques. Although this paper follows upon our extensive prior behavioral work (Planton et al.), we agree that it should stand alone and that therefore the models need to be described more fully. We have now added a formal description of the LoT in the subsection The Language of Thought for binary sequences in the Results section and have added a formal and verbal description of the selected sequences in Figure 1-figure supplement 1. Furthermore, we added a model comparison similar to the one done in (Planton et al., 2021 PLOS Computational Biology). This analysis is now included in Figure 2 and in the Behavioral data subsection of the Results section. It replicates previous behavioral results obtained in Planton et al., 2021 PLOS Computational Biology, namely that complexity, as measured by minimal description length in the binary version of the “language of geometry” was the best predictor of participants’ behaviour.
Interestingly, we found that the model that considered both complexity and surprise had even lower AIC suggesting that statistical learning is simultaneously occurring in the brain (Brain signatures of a multiscale process of sequence learning in humans, M Maheu, S Dehaene, F Meyniel - eLife, 2019). In this respect, we do not consider surprise from transition probabilities as an alternative model but rather as a mechanism that is occurring in parallel to sequence compression. The main goal of this work was to determine how sequence processing was affected by sequence structure, captured by the language of thought. In this line, we didn't select the tested sequences in order to investigate statistical learning but, instead, chose them with similar global statistical properties.
The MEG experiment provided us with the opportunity to separate temporally the contributions of statistical mechanisms from the ones of sequence compression according to the language of thought. Indeed, contrary to the fMRI experiment, we could model at the item level the statistical properties of individual sounds. We report the results when accounting jointly for statistical processing and LoT-complexity in Supplementary materials.
The different models considered in previous work didn’t need to be trained. The sequence complexity they provided could be analytically computed based on sequence minimal description length.
Furthermore, the manuscript needs a clear motivation for the type of sequences and some methodological decisions. Central here is the quadratic trend selectively used for the fMRI analysis but not for the other datasets.
To design the MEG, we had to decrease the number of sequences from 10 to 7. We selected them based on the LoT-complexity and the type of sequence information they spanned. As a consequence, the predictors for linear and quadratic complexity are very correlated (82%). Unfortunately, due to low SNR, this doesn’t allow to robustly account for the contributions of quadratic complexity in the MEG-recorded brain signals. Still, in response to the referee, we performed a linear regression as a function of quadratic complexity on the residuals of the regression as function of statistics and complexity that we report here. No significant clusters were found for habituation and standard trials but two were found (corresponding to the same topography) for deviant trials for late time-points.
In Author response image 1 regression coefficients for the quadratic complexity regressor regressed on the residuals of the surprise from transition probabilities and complexity. In Author response image 2, 2 significant clusters were found for the deviant sounds.
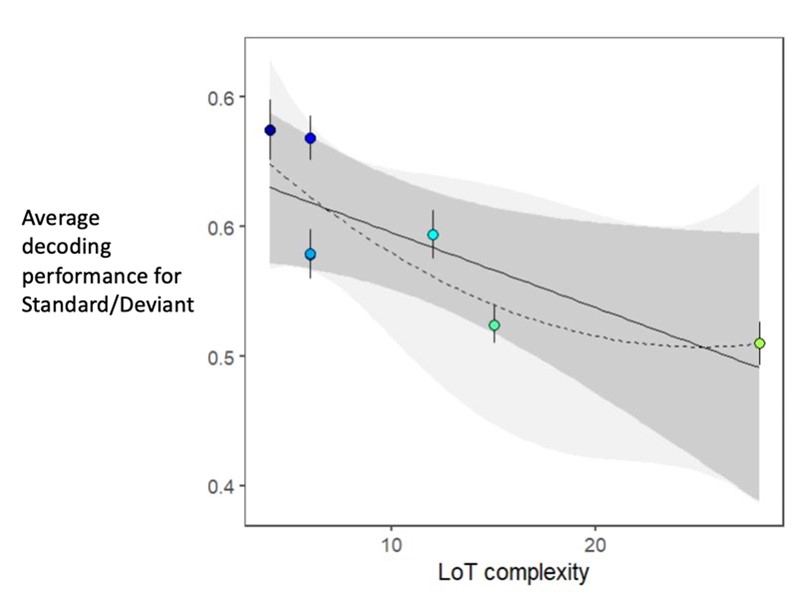
We also averaged the decoding scores from Figure7.A over the time-window obtained from the temporal cluster-based permutation test (see Author response image 2). The choice of complexity values didn’t allow any clear assessment of the contribution of the quadratic complexity term.
In summary, in the current design, we do not think that the number of tested sequences allows us to clearly conclude that no quadratic effect can be found for Habituation and Standard trials. We would need to re-design an experiment to test specifically the quadratic complexity contribution to brain signals in MEG.
Author response image 1.
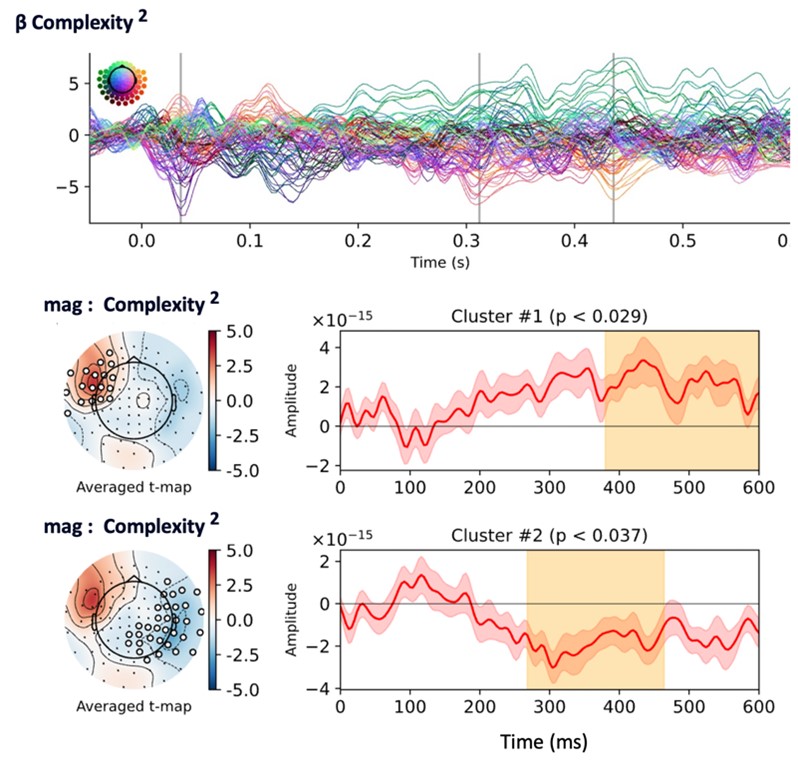
Author response image 2.
Also, the description of the linear mixed models is missing (e.g., the random effect structure, e.g., see Bates, D., Kliegl, R., Vasishth, S., & Baayen, H. (2015). Parsimonious mixed models. arXiv preprint arXiv:1506.04967.). Moreover, sample sizes have not been justified by a power analysis.
The linear mixed model that is considered in this work is very simple, it only uses Subject as a random variable. This is now stated clearly in the corresponding part in the Experimental procedures section:
To test whether subject performance correlated with LoT complexity, we performed linear regressions on group-averaged data, as well linear mixed models including participant as the (only) random factor. The random effect structure of the mixed models was kept minimal, and did not include any random slopes, to avoid the convergence issues often encountered when attempting to fit more complex models.
-
eLife assessment
This article brings to bear a useful, extensive set of behavioral methods and neural data to report that activity in numerous cortical regions robustly covaries with the complexity of tone sequences encoded in memory. In its current state, the findings are solid but deserve further analysis to arrive at more convincing conclusions.
-
Reviewer #1 (Public Review):
The manuscript investigates how humans store temporal sequences of tones in working memory. The authors mainly focus on a theory named "Language of thought" (LoT). Here the structure of a stimulus sequence can be stored in a tree structure that integrates the dependencies of a stimulus stored in working memory. To investigate the LoT hypothesis, participants listened to multiple stimulus sequences that varied in complexity (e.g., alternating tones vs. nearly random sequence). Simultaneously, the authors collected fMRI or MEG data to investigate the neuronal correlates of LoT complexity in working memory. Critical analysis was based on a deviant tone that violated the stored sequence structure. Deviant detection behavior and a bracketing task allowed a behavioral analysis.
Results showed accurate bracketing …
Reviewer #1 (Public Review):
The manuscript investigates how humans store temporal sequences of tones in working memory. The authors mainly focus on a theory named "Language of thought" (LoT). Here the structure of a stimulus sequence can be stored in a tree structure that integrates the dependencies of a stimulus stored in working memory. To investigate the LoT hypothesis, participants listened to multiple stimulus sequences that varied in complexity (e.g., alternating tones vs. nearly random sequence). Simultaneously, the authors collected fMRI or MEG data to investigate the neuronal correlates of LoT complexity in working memory. Critical analysis was based on a deviant tone that violated the stored sequence structure. Deviant detection behavior and a bracketing task allowed a behavioral analysis.
Results showed accurate bracketing and fast/correct responses when LoT complexity is low. fMRI data showed that LoT complexity correlated with the activation of 14 clusters. MEG data showed that LoT complexity correlated mainly with activation from 100-200 ms after stimulus onset. These and other analyses presented in the manuscript lead the authors to conclude that such tone sequences are represented in human memory using LoT in contrast to alternative representations that rely on distinct memory slot representations.
Strengths
The study provides a concise and easily accessible introduction. The task and stimuli are well described and allow a good understanding of what participants experience while their brain activation is recorded. Results are extensive as they include multiple behavioral investigations and brain activation data from two different measurement modalities. The presentation of the behavioral results is intuitive. The analysis provided a direct comparison of the LoT with an alternative model based on estimating a transition-probability measure of surprise.
For the fMRI data, the whole brain analysis was accompanied by detailed region of interest analyses, including time course analysis, for the activation clusters correlated with LoT complexity. In addition, the activation clusters have been set in relation (overlap and region of interest analyses) to a math and a language localizer. For the MEG data, the authors investigated the LoT complexity effect based on linear regression, including an analysis that also included transitional probabilities and multivariate decoding analysis. The discussion of the results focused on comparing the activation patterns of the task with the localizer tasks. Overall, the authors have provided considerable new data in multiple modalities on a well-designed experiment investigating how humans represent sequences in auditory working memory.
Weaknesses
The primary issue of the manuscript is the missing formal description of the LoT model and alternatives, inconsistencies in the model comparisons, and no clear argumentation that would allow the reader to understand the selection of the alternative model. Similar to a recent paper by similar authors (Planton et al., 2021 PLOS Computational Biology), an explicit model comparison analysis would allow a much stronger conclusion. Also, these analyses would provide a more extensive evidence base for the favored LoT model. Needed would be a clear argumentation for why the transitional probabilities were identified as the most optimal alternative model for a critical test. A clear description of the models (e.g., how many free parameters) and a description of the simulation procedure (e.g., are they trained, etc.) Here it would be strongly advised to provide the scripts that allow others to reproduce the simulations.
Furthermore, the manuscript needs a clear motivation for the type of sequences and some methodological decisions. Central here is the quadratic trend selectively used for the fMRI analysis but not for the other datasets. Also, the description of the linear mixed models is missing (e.g., the random effect structure, e.g., see Bates, D., Kliegl, R., Vasishth, S., & Baayen, H. (2015). Parsimonious mixed models. arXiv preprint arXiv:1506.04967.). Moreover, sample sizes have not been justified by a power analysis.
-
Reviewer #2 (Public Review):
Any stimulus that enters the human mind is in one way or another other compressed. A drawing with hundreds of lines might be turned into "picture of a seescape", a complex set of harmonically overlapping sine waves might be turned into "sad piano chord", and a weird set of utterances incomprehensible to most animals could be turned into "someone reading a review aloud" if prior experience permits. Understanding this process is essential to understanding the human mind. Understanding compression is even more critical to understanding working memory that - in its limited capacity - can most profit from compression, abstraction, or chunking.
Here, the authors provide some insight into how a sequence of binary pitch might be compressed during encoding into memory. They use a previously developed method to …
Reviewer #2 (Public Review):
Any stimulus that enters the human mind is in one way or another other compressed. A drawing with hundreds of lines might be turned into "picture of a seescape", a complex set of harmonically overlapping sine waves might be turned into "sad piano chord", and a weird set of utterances incomprehensible to most animals could be turned into "someone reading a review aloud" if prior experience permits. Understanding this process is essential to understanding the human mind. Understanding compression is even more critical to understanding working memory that - in its limited capacity - can most profit from compression, abstraction, or chunking.
Here, the authors provide some insight into how a sequence of binary pitch might be compressed during encoding into memory. They use a previously developed method to encapsulate sequences of 16 high and low pitches using a math-like description scheme (Planton et al., 2021). One can think of this scheme as a "language", "a categorization model", or "a process of segmenting patterns", but its central role in the experiment is to derive a 'rough' measure of complexity that is shown to covary with behavioral data, here and in prior work (Planton et al., 2021).
This language seems to be particularly useful in the context of this highly regularized task, where the set of possible sequences is limited to 20 (out of an overall number of 65.536 imaginable sequences). Instead of finding structures in random sequences, subjects can be expected to quickly learn that their task is to detect which particular structure (of a fairly limited class) is to be found in the given sequence. It is unclear whether such a language would also be useful for sequences of more natural stimuli that motivate the authors' research (e.g. syllables, tones, or shapes). What both more natural compression and the compression used in this task have in common is that long-term memory might play an instrumental role during the compression.
Thus, the authors provide clear evidence that these sequences are being compressed and some evidence that the compression used shares some features with the compression model employed, here. The neural data are consistent with this interpretation.
Regardless of our disagreement with the interpretation of the results the authors put forward, we find the research presented here elegantly designed, well grounded in a series of prior work, and inspiring. There is little known about the representation of sequences in memory and during perception and we believe that this work is a notable and helpful addition to our understanding of this question.
-
