Deep learning-based feature extraction for prediction and interpretation of sharp-wave ripples in the rodent hippocampus
Curation statements for this article:-
Curated by eLife

Evaluation Summary:
This paper will be of interest to the neuroscience community studying brain oscillations. It presents a new method to detect sharp-wave ripples in the hippocampus with deep learning techniques, instead of the more traditional signal processing approach. The overall detection performance improves and this technique may help identify and characterize previously undetected physiological events.
(This preprint has been reviewed by eLife. We include the public reviews from the reviewers here; the authors also receive private feedback with suggested changes to the manuscript. The reviewers remained anonymous to the authors.)
This article has been Reviewed by the following groups
Discuss this preprint
Start a discussion What are Sciety discussions?Listed in
- Evaluated articles (eLife)
Abstract
Local field potential (LFP) deflections and oscillations define hippocampal sharp-wave ripples (SWRs), one of the most synchronous events of the brain. SWRs reflect firing and synaptic current sequences emerging from cognitively relevant neuronal ensembles. While spectral analysis have permitted advances, the surge of ultra-dense recordings now call for new automatic detection strategies. Here, we show how one-dimensional convolutional networks operating over high-density LFP hippocampal recordings allowed for automatic identification of SWR from the rodent hippocampus. When applied without retraining to new datasets and ultra-dense hippocampus-wide recordings, we discovered physiologically relevant processes associated to the emergence of SWR, prompting for novel classification criteria. To gain interpretability, we developed a method to interrogate the operation of the artificial network. We found it relied in feature-based specialization, which permit identification of spatially segregated oscillations and deflections, as well as synchronous population firing typical of replay. Thus, using deep learning-based approaches may change the current heuristic for a better mechanistic interpretation of these relevant neurophysiological events.
Article activity feed
-

Author Response:
Reviewer #1 (Public Review):
In this manuscript, the authors leverage novel computational tools to detect, classify and extract information underlying sharp-wave ripples, and synchronous events related to memory. They validate the applicability of their method to several datasets and compare it with a filtering method. In summary, they found that their convolutional neural network detection captures more events than the commonly used filter method. This particular capability of capturing additional events which traditional methods don't detect is very powerful and could open important new avenues worth further investigation. The manuscript in general will be very useful for the community as it will increase the attention towards new tools that can be used to solve ongoing questions in hippocampal physiology.
We …
Author Response:
Reviewer #1 (Public Review):
In this manuscript, the authors leverage novel computational tools to detect, classify and extract information underlying sharp-wave ripples, and synchronous events related to memory. They validate the applicability of their method to several datasets and compare it with a filtering method. In summary, they found that their convolutional neural network detection captures more events than the commonly used filter method. This particular capability of capturing additional events which traditional methods don't detect is very powerful and could open important new avenues worth further investigation. The manuscript in general will be very useful for the community as it will increase the attention towards new tools that can be used to solve ongoing questions in hippocampal physiology.
We thank the reviewer for the constructive comments and appreciation of the work.
Additional minor points that could improve the interpretation of this work are listed below:
- Spectral methods could also be used to capture the variability of events if used properly or run several times through a dataset. I think adjusting the statements where the authors compare CNN with traditional filter detections could be useful as it can be misleading to state otherwise.
We thank the reviewer for this suggestion. We would like to emphasize that we do not advocate at all for disusing filters. We feel that a combination of methods is required to improve our understanding of the complex electrophysiological processes underlying SWR. We have adjusted the text as suggested. In particular, a) we removed the misleading sentence from the abstract, and instead declared the need for new automatic detection strategies; b) we edited the introduction similarly, and clarified the need for improved online applications.
- The authors show that their novel method is able to detect "physiological relevant processes" but no further analysis is provided to show that this is indeed the case. I suggest adjusting the statement to "the method is able to detect new processes (or events)".
We have corrected text as suggested. In particular, we declare that “The new method, in combination with community tagging efforts and optimized filter, could potentially facilitate discovery and interpretation of the complex neurophysiological processes underlying SWR.” (page 12).
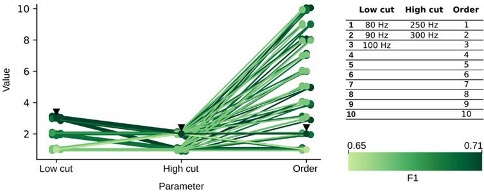
- In Fig.1 the authors show how they tune the parameters that work best for their CNN method and from there they compare it with a filter method. In order to offer a more fair comparison analogous tuning of the filter parameters should be tested alongside to show that filters can also be tuned to improve the detection of "ground truth" data.
Thank you for this comment. As explained before, see below the results of the parameter study for the filter in the very same sessions used for training the CNN. The parameters chosen (100- 300Hz band, order 2) provided maximal performance in the test set. Therefore, both methods are similarly optimized along training. This is now included (page 4): “In order to compare CNN performance against spectral methods, we implemented a Butterworth filter, which parameters were optimized using the same training set (Fig.1-figure supplement 1D).”
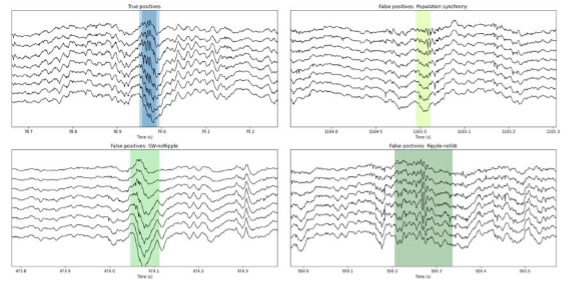
- Showing a manual score of the performance of their CNN method detection with false positive and false negative flags (and plots) would be clarifying in order to get an idea of the type of events that the method is able to detect and fails to detect.
We have added information of the categories of False Positives for both the CNN and the filter in the new Fig.4F. We have also prepared an executable figure to show examples and to facilitate understanding how the CNN works. See new Fig.5 and executable notebook https://colab.research.google.com/github/PridaLab/cnn-ripple-executable-figure/blob/main/cnn-ripple-false-positive-examples.ipynb
- In fig 2E the authors show the differences between CNN with different precision and the filter method, while the performance is better the trends are extremely similar and the numbers are very close for all comparisons (except for the recall where the filter clearly performs worse than CNN).
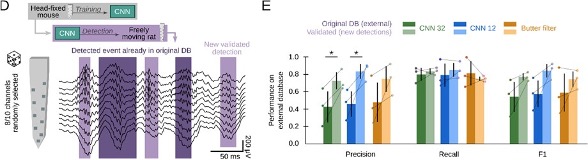
This refers to the external dataset (Grosmark and Buzsaki 2016), which is now in the new Fig.3E. To address this point and to improve statistical report, we have added more data resulting in 5 sessions from 2 rats. Data confirm better performance of CNN model versus the filter. The purpose of this figure is to show the effect of the definition of the ground truth on the performance by different methods, and also the proper performance of the CNN on external datasets without retraining. Please, note that in Grosmark and Buzsaki, SWR detection was conditioned on the
coincidence of both population synchrony and LFP definition thus providing a “partial ground truth” (i.e. SWR without population firing were not annotated in the dataset).
- The authors acknowledge that various forms of SWRs not consistent with their common definition could be captured by their method. But theoretically, it could also be the case that, due to the spectral continuum of the LFP signals, noisy features of the LFP could also be passed as "relevant events"? Discussing this point in the manuscript could help with the context of where the method might be applied in the future.
As suggested, we have mentioned this point in the revised version. In particular: “While we cannot discard noisy detection from a continuum of LFP activity, our categorization suggest they may reflect processes underlying buildup of population events (de la Prida et al., 2006). In addition, the ability of CA3 inputs to bring about gamma oscillations and multi-unit firing associated with sharp-waves is already recognized (Sullivan et al., 2011), and variability of the ripple power can be related with different cortical subnetworks (Abadchi et al., 2020; Ramirez- Villegas et al., 2015). Since the power spectral level operationally defines the detection of SWR, part of this microcircuit intrinsic variability may be escaping analysis when using spectral filters” (page 16).
- In fig. 5 the authors claim that there are striking differences in firing rate and timings of pyramidal cells when comparing events detected in different layers (compare to SP layer). This is not very clear from the figure as the plots 5G and 5H show that the main differences are when compare with SO and SLM.
We apologize for generating confusion. We meant that the analysis was performed by comparing properties of SWR detected at SO, SR and SLM using z- values scored by SWR detected at SP only). We clarified this point in the revised version: “We found larger sinks and sources for SWR that can be detected at SLM and SR versus those detected at SO (Fig.7G; z-scored by mean values of SWR detected at SP only).” (page 14).
- Could the above differences be related to the fact that the performance of the CNN could have different percentages of false-positive when applied to different layers?
The rate of FP is similar/different across layers: 0.52 ± 0.21 for SO, 0.50 ± 0.21 for SR and 0.46 ± 0.19 for SLM. This is now mentioned in the text: “No difference in the rate of False Positives between SO (0.52 ± 0.21), SR (0.50 ± 0.21) and SLM (0.46 ± 0.19) can account for this effect.” (page 12)
Alternatively, could the variability be related to the occurrence (and detection) of similar events in neighboring spectral bands (i.e., gamma events)? Discussion of this point in the manuscript would be helpful for the readers.
We have discussed this point: “While we cannot discard noisy detection from a continuum of LFP activity, our categorization suggest they may reflect processes underlying buildup of population events (de la Prida et al., 2006). In addition, the ability of CA3 inputs to bring about gamma oscillations and multi-unit firing associated with sharp-waves is already recognized (Sullivan et al., 2011), and variability of the ripple power can be related with different cortical subnetworks (Abadchi et al., 2020; Ramirez-Villegas et al., 2015).” (Page 16)
Overall, I think the method is interesting and could be very useful to detect more nuance within hippocampal LFPs and offer new insights into the underlying mechanisms of hippocampal firing and how they organize in various forms of network events related to memory.
We thank the reviewer for constructive comments and appreciation of the value of our work.
Reviewer #2 (Public Review):
Navas-Olive et al. provide a new computational approach that implements convolutional neural networks (CNNs) for detecting and characterizing hippocampal sharp-wave ripples (SWRs). SWRs have been identified as important neural signatures of memory consolidation and retrieval, and there is therefore interest in developing new computational approaches to identify and characterize them. The authors demonstrate that their network model is able to learn to identify SWRs by showing that, following the network training phase, performance on test data is good. Performance of the network varied by the human expert whose tagging was used to train it, but when experts' tags were combined, performance of the network improved, showing it benefits from multiple input. When the network trained on one dataset is applied to data from different experimental conditions, performance was substantially lower, though the authors suggest that this reflected erroneous annotation of the data, and once corrected performance improved. The authors go on to analyze the LFP patterns that nodes in the network develop preferences for and compare the network's performance on SWRs and non-SWRs, both providing insight and validation about the network's function. Finally, the authors apply the model to dense Neuropixels data and confirmed that SWR detection was best in the CA1 cell layer but could also be detected at more distant locations.
The key strengths of the manuscript lay in a convincing demonstration that a computational model that does not explicitly look for oscillations in specific frequency bands can nevertheless learn to detect them from tagged examples. This provides insight into the capabilities and applications of convolutional neural networks. The manuscript is generally clearly written and the analyses appear to have been carefully done.
We thank the reviewer for the summary and for highlighting the strengths of our work.
While the work is informative about the capabilities of CNNs, the potential of its application for neuroscience research is considerably less convincing. As the authors state in the introduction, there are two potential key benefits that their model could provide (for neuroscience research): 1. improved detection of SWRs and 2. providing additional insight into the nature of SWRs, relative to existing approaches. To this end, the authors compare the performance of the CNN to that of a Butterworth filter. However, there are a number of major issues that limit the support for the authors' claims:
Please, see below the answers to specific questions, which we hope clarify the validity of our approach
• Putting aside the question of whether the comparison between the CNN and the filter is fair (see below), it is unclear if even as is, the performance of the CNN is better than a simple filter. The authors argue for this based on the data in Fig. 1F-I. However, the main result appears to be that the CNN is less sensitive to changes in the threshold, not that it does better at reasonable thresholds.
This comment now refers to the new Fig.2A (offline detection) and Fig.2C,D (online detection). Starting from offline detection, yes, the CNN is less sensitive than the filter and that has major consequences both offline and online. For the filter to reach it best performance, the threshold has to be tuned which is a time-consuming process. Importantly, this is only doable when you know the ground truth. In practical terms, most lab run a semi-automatic detection approach where they first detect events and then they are manually validated. The fact that the filter is more sensible to thresholds makes this process very tedious. Instead, the CNN is more stable.
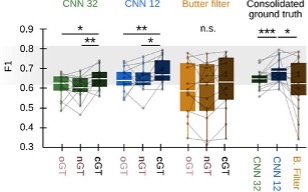
In trying to be fair, we also tested the performance of the CNN and the filter at their best performance (i.e. looking for the threshold f¡providing the best matching with the ground truth). This is shown at Fig.3A. There are no differences between methods indicating the CNN meet the gold standard provided the filter is optimized. Note again this is only possible if you know the ground truth because optimization is based in looking for the best threshold per session.
Importantly, both methods reach their best performance at the expert’s limit (gray band in Fig.3A,B). They cannot be better than the individual ground truth. This is why we advocate for community tagging collaborations to consolidate sharp-wave ripple definitions.
Moreover, the mean performance of the filter across thresholds appears dramatically dampened by its performance on particularly poor thresholds (Fig. F, I, weak traces). How realistic these poorly tested thresholds are is unclear. The single direct statistical test of difference in performance is presented in Fig. 1H but it is unclear if there is a real difference there as graphically it appears that animals and sessions from those animals were treated as independent samples (and comparing only animal averages or only sessions clearly do not show a significant difference).
Please, note this refers to online detection. We are not sure to understand the comment on whether the thresholds are realistic. To clarify, we detect SWR online using thresholds we similarly optimize for the filter and the CNN over the course of the experiment. This is reported in Fig.2C as both, per session and per animals, reaching statistical differences (we added more experiments to increase statistical power). Since, online defined thresholds may still not been the best, we then annotated these data and run an additional posthoc offline optimization analysis which is presented in Fig.2D. We hope this is now more clear in the revised version.
Finally, the authors show in Fig. 2A that for the best threshold the CNN does not do better than the filter. Together, these results suggest that the CNN does not generally outperform the filter in detecting SWRs, but only that it is less sensitive to usage of extreme thresholds.
We hope this is now clarified. See our response to your first bullet point
Indeed, I am not convinced that a non-spectral method could even theoretically do better than a spectral method to detect events that are defined by their spectrum, assuming all other aspects are optimized (such as combining data from different channels and threshold setting)
As can be seen in the responses to the editor synthesis, we have optimized the filter parameter similarly (new Fig.1-supp-1D) and there is no improvement by using more channels (see below). In any case, we would like to emphasize that we do not advocate at all for disusing filters. We feel that a combination of methods is required to improve our understanding of the complex electrophysiological processes underlying SWR.
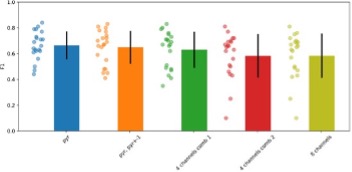
• The CNN network is trained on data from 8 channels but it appears that the compared filter is run on a single channel only. This is explicitly stated for the online SWR detection and presumably, that is the case for the offline as well. This unfair comparison raises the possibility that whatever improved performance the CNN may have may be due to considerably richer input and not due to the CNN model itself. The authors state that a filter on the data from a single channel is the standard, but many studies use various "consensus" heuristics, e.g. in which elevated ripple power is required to be detected on multiple channels simultaneously, which considerably improves detection reliability. Even if this weren't the case, because the CNN learns how to weight each channel, to argue that better performance is due to the nature of the CNN it must be compared to an algorithm that similarly learns to optimize these weights on filtered data across the same number of channels. It is very likely that if this were done, the filter approach would outperform the CNN as its performance with a single channel is comparable.
We appreciate this comment. Using one channel to detect SWR is very common for offline detection followed by manual curation. In some cases, a second channel is used either to veto spurious detections (using a non-ripple channel) or to confirm detection (using a second ripple channel and/or a sharp-wave) (Fernandez-Ruiz et al., 2019). Many others use detection of population firing together with the filter to identify replay (such as in Grosmark and Buzsaki 2019, where ripples were conditioned on the coincidence of both population firing and LFP detected ripples). To address this comment, we compared performance using different combinations of channels, from the standard detection at the SP layer (pyr) up to 4 and 8 channels around SP using the consensus heuristics. As can be seen filter performance is consistent across configurations and using 8 channels is not improving detection. We clarify this in the revised version: ”We found no effect of the number of channels used for the filter (1, 4 and 8 channels), and chose that with the higher ripple power” (see caption of Fig.1-supp-1D).
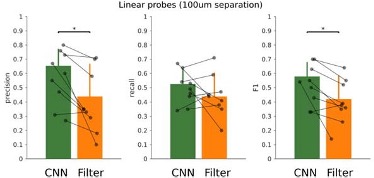
• Related to the point above, for the proposed CNN model to be a useful tool in the neuroscience field it needs to be amenable to the kind of data and computational resources that are common in the field. As the network requires 8 channels situated in close proximity, the network would not be relevant for numerous studies that use fewer or spaced channels. Further, the filter approach does not require training and it is unclear how generalizable the current CNN model is without additional network training (see below). Together, these points raise the concern that even if the CNN performance is better than a filter approach, it would not be usable by a wide audience.
Thank you for this comment. To handle with different input channel configurations, we have developed an interpolation approach, which transform any data into 8-channel inputs. We are currently applying the CNN without re-training to data from several labs using different electrode number and configurations, including tetrodes, linear silicon probes and wires. Results confirm performance of the CNN. Since we cannot disclose these third-party data here, we have looked for a new dataset from our own lab to illustrate the case. See below results from 16ch silicon probes (100 um inter-electrode separation), where the CNN performed better than the filter (F1: p=0.0169; Precision, p=0.0110; 7 sessions, from 3 mice). We found that the performance of the CNN depends on the laminar LFP profile, as Neuropixels data illustrate.
• A key point is whether the CNN generalizes well across new datasets as the authors suggest. When the model trained on mouse data was applied to rat data from Grosmark and Buzsaki, 2016, precision was low. The authors state that "Hence, we evaluated all False Positive predictions and found that many of them were actually unannotated SWR (839 events), meaning that precision was actually higher". How were these events judged as SWRs? Was the test data reannotated?
We apologize for not explaining this better in the original version. We choose Grosmark and Buzsaki 2016 because it provides an “incomplete ground truth”, since (citing their Methods) “Ripple events were conditioned on the coincidence of both population synchrony events, and LFP detected ripples”. This means there are LFP ripples not included in their GT. This dataset provides a very good example of how the experimental goal (examining replay and thus relying in population firing plus LFP definitions) may limit the ground truth.
Please, note we use the external dataset for validation purposes only. The CNN model was applied without retraining, so it also helps to exemplify generalization. Consistent with a partial ground truth, the CNN and the filter recalled most of the annotated events, but precision was low. By manually validating False Positive detections, we re-annotated the external dataset and both the CNN and the filter increased precision.
To make the case clearer, we now include more sessions to increase the data size and test for statistical effects (Fig.3E). We also changed the example to show more cases of re-annotated events (Fig.3D). We have clarified the text: “In that work, SWR detection was conditioned on the coincidence of both population synchrony and LFP definition, thus providing a “partial ground truth” (i.e. SWR without population firing were not annotated in the dataset).” (see page 7).
• The argument that the network improves with data from multiple experts while the filter does not requires further support. While Fig. 1B shows that the CNN improves performance when the experts' data is combined and the filter doesn't, the final performance on the consolidated data does not appear better in the CNN. This suggests that performance of the CNN when trained on data from single experts was lower to start with.
This comment refers to the new Fig.3B. We apologize for not have had included a between- method comparison in the original version. To address this, we now include a one-way ANOVA analysis for the effect of the type of the ground truth on each method, and an independent one- way ANOVA for the effect of the method in the consolidated ground truth. To increase statistical power we have added more data. We also detected some mistake with duplicated data in the original figure, which was corrected. Importantly, the rationale behind experts’ consolidated data is that there is about 70% consistency between experts and so many SWR remain not annotated in the individual ground truths. These are typically some ambiguous events, which may generate discussion between experts, such as sharp-wave with population firing and few ripple cycles. Since the CNN is better in detecting them, this is the reason supporting they improve performance when data from multiple experts are integrated.
Further, regardless of the point in the bullet point above, the data in Fig. 1E does not convincingly show that the CNN improves while the filter doesn't as there are only 3 data points per comparison and no effect on F1.
Fig.1E shows an example, so we guess the reviewer refers to the new Fig.2C, which show data on online operation, where we originally reported the analysis per session and per animal separately with only 3 mice. We have run more experiments to increase the data size and test for statistical effects (8 sessions, 5 mice; per sessions p=0.0047; per mice p=0.033; t-test). This is now corrected in the text and Fig.1C, caption. Please, note that a posthoc offline evaluation of these online sessions confirmed better performance of the CNN versus the filter, for all normalized thresholds (Fig.2D).
• Apart from the points above regarding the ability of the network to detect SWRs, the insight into the nature of SWRs that the authors suggest can be achieved with CNNs is limited. For example, the data in Fig. 3 is a nice analysis of what the components of the CNN learn to identify, but the claim that "some predictions not consistent with the current definition of SWR may identify different forms of population firing and oscillatory activities associated to sharp-waves" is not thoroughly supported. The data in Fig. 4 is convincing in showing that the network better identifies SWRs than non-SWRs, but again the insight is about the network rather than about SWRs.
In the revised version, have now include validation of all false positives detected by the CNN and the filter (Fig.4F). To facilitate the reader examining examples of True Positive and False Positive detection we also include a new figure (Fig.5), which comes with the executable code (see page 9). We also include comparisons of the features of TP events detected by both methods (Fig.2B), where is shown that SWR events detected by the CNN exhibited features more similar to those of the ground truth (GT), than those detected by the filter. We feel the entire manuscript provides support to these claims.
Finally, the application of the model on Neuropixels data also nicely demonstrates the applicability of the model on this kind of data but does not provide new insight regarding SWRs.
We respectfully disagree. Please, note that application to ultra-dense Neuropixels not only apply the model to an entirely new dataset without retraining, but it shows that some SWR with larger sinks and sources can be actually detected at input layers (SO, SR and SLM). Importantly, those events result in different firing dynamics providing mechanistic support for heterogeneous behavior underlying, for instance, replay.
In summary, the authors have constructed an elegant new computational tool and convincingly shown its validity in detecting SWRs and applicability to different kinds of data. Unfortunately, I am not convinced that the model convincingly achieves either of its stated goals: exceeding the performance of SWR detection or providing new insights about SWRs as compared to considerably simpler and more accessible current methods.
We thank you again for your constructive comments. We hope you are now convinced on the value of the new method in light to the new added data.
-
Evaluation Summary:
This paper will be of interest to the neuroscience community studying brain oscillations. It presents a new method to detect sharp-wave ripples in the hippocampus with deep learning techniques, instead of the more traditional signal processing approach. The overall detection performance improves and this technique may help identify and characterize previously undetected physiological events.
(This preprint has been reviewed by eLife. We include the public reviews from the reviewers here; the authors also receive private feedback with suggested changes to the manuscript. The reviewers remained anonymous to the authors.)
-
Reviewer #1 (Public Review):
In this manuscript, the authors leverage novel computational tools to detect, classify and extract information underlying sharp-wave ripples, and synchronous events related to memory. They validate the applicability of their method to several datasets and compare it with a filtering method. In summary, they found that their convolutional neural network detection captures more events than the commonly used filter method. This particular capability of capturing additional events which traditional methods don't detect is very powerful and could open important new avenues worth further investigation. The manuscript in general will be very useful for the community as it will increase the attention towards new tools that can be used to solve ongoing questions in hippocampal physiology.
Additional minor points that …
Reviewer #1 (Public Review):
In this manuscript, the authors leverage novel computational tools to detect, classify and extract information underlying sharp-wave ripples, and synchronous events related to memory. They validate the applicability of their method to several datasets and compare it with a filtering method. In summary, they found that their convolutional neural network detection captures more events than the commonly used filter method. This particular capability of capturing additional events which traditional methods don't detect is very powerful and could open important new avenues worth further investigation. The manuscript in general will be very useful for the community as it will increase the attention towards new tools that can be used to solve ongoing questions in hippocampal physiology.
Additional minor points that could improve the interpretation of this work are listed below:
- Spectral methods could also be used to capture the variability of events if used properly or run several times through a dataset. I think adjusting the statements where the authors compare CNN with traditional filter detections could be useful as it can be misleading to state otherwise.
- The authors show that their novel method is able to detect "physiological relevant processes" but no further analysis is provided to show that this is indeed the case. I suggest adjusting the statement to "the method is able to detect new processes (or events)".
- In Fig.1 the authors show how they tune the parameters that work best for their CNN method and from there they compare it with a filter method. In order to offer a more fair comparison analogous tuning of the filter parameters should be tested alongside to show that filters can also be tuned to improve the detection of "ground truth" data.
- Showing a manual score of the performance of their CNN method detection with false positive and false negative flags (and plots) would be clarifying in order to get an idea of the type of events that the method is able to detect and fails to detect.
- In fig 2E the authors show the differences between CNN with different precision and the filter method, while the performance is better the trends are extremely similar and the numbers are very close for all comparisons (except for the recall where the filter clearly performs worse than CNN).
- The authors acknowledge that various forms of SWRs not consistent with their common definition could be captured by their method. But theoretically, it could also be the case that, due to the spectral continuum of the LFP signals, noisy features of the LFP could also be passed as "relevant events"? Discussing this point in the manuscript could help with the context of where the method might be applied in the future.
- In fig. 5 the authors claim that there are striking differences in firing rate and timings of pyramidal cells when comparing events detected in different layers (compare to SP layer). This is not very clear from the figure as the plots 5G and 5H show that the main differences are when compare with SO and SLM.
- Could the above differences be related to the fact that the performance of the CNN could have different percentages of false-positive when applied to different layers? Alternatively, could the variability be related to the occurrence (and detection) of similar events in neighboring spectral bands (i.e., gamma events)? Discussion of this point in the manuscript would be helpful for the readers.
Overall, I think the method is interesting and could be very useful to detect more nuance within hippocampal LFPs and offer new insights into the underlying mechanisms of hippocampal firing and how they organize in various forms of network events related to memory.
-
Reviewer #2 (Public Review):
Navas-Olive et al. provide a new computational approach that implements convolutional neural networks (CNNs) for detecting and characterizing hippocampal sharp-wave ripples (SWRs). SWRs have been identified as important neural signatures of memory consolidation and retrieval, and there is therefore interest in developing new computational approaches to identify and characterize them. The authors demonstrate that their network model is able to learn to identify SWRs by showing that, following the network training phase, performance on test data is good. Performance of the network varied by the human expert whose tagging was used to train it, but when experts' tags were combined, performance of the network improved, showing it benefits from multiple input. When the network trained on one dataset is applied to …
Reviewer #2 (Public Review):
Navas-Olive et al. provide a new computational approach that implements convolutional neural networks (CNNs) for detecting and characterizing hippocampal sharp-wave ripples (SWRs). SWRs have been identified as important neural signatures of memory consolidation and retrieval, and there is therefore interest in developing new computational approaches to identify and characterize them. The authors demonstrate that their network model is able to learn to identify SWRs by showing that, following the network training phase, performance on test data is good. Performance of the network varied by the human expert whose tagging was used to train it, but when experts' tags were combined, performance of the network improved, showing it benefits from multiple input. When the network trained on one dataset is applied to data from different experimental conditions, performance was substantially lower, though the authors suggest that this reflected erroneous annotation of the data, and once corrected performance improved. The authors go on to analyze the LFP patterns that nodes in the network develop preferences for and compare the network's performance on SWRs and non-SWRs, both providing insight and validation about the network's function. Finally, the authors apply the model to dense Neuropixels data and confirmed that SWR detection was best in the CA1 cell layer but could also be detected at more distant locations.
The key strengths of the manuscript lay in a convincing demonstration that a computational model that does not explicitly look for oscillations in specific frequency bands can nevertheless learn to detect them from tagged examples. This provides insight into the capabilities and applications of convolutional neural networks. The manuscript is generally clearly written and the analyses appear to have been carefully done.
While the work is informative about the capabilities of CNNs, the potential of its application for neuroscience research is considerably less convincing. As the authors state in the introduction, there are two potential key benefits that their model could provide (for neuroscience research): 1. improved detection of SWRs and 2. providing additional insight into the nature of SWRs, relative to existing approaches. To this end, the authors compare the performance of the CNN to that of a Butterworth filter. However, there are a number of major issues that limit the support for the authors' claims:
• Putting aside the question of whether the comparison between the CNN and the filter is fair (see below), it is unclear if even as is, the performance of the CNN is better than a simple filter. The authors argue for this based on the data in Fig. 1F-I. However, the main result appears to be that the CNN is less sensitive to changes in the threshold, not that it does better at reasonable thresholds. Moreover, the mean performance of the filter across thresholds appears dramatically dampened by its performance on particularly poor thresholds (Fig. F, I, weak traces). How realistic these poorly tested thresholds are is unclear. The single direct statistical test of difference in performance is presented in Fig. 1H but it is unclear if there is a real difference there as graphically it appears that animals and sessions from those animals were treated as independent samples (and comparing only animal averages or only sessions clearly do not show a significant difference). Finally, the authors show in Fig. 2A that for the best threshold the CNN does not do better than the filter. Together, these results suggest that the CNN does not generally outperform the filter in detecting SWRs, but only that it is less sensitive to usage of extreme thresholds. Indeed, I am not convinced that a non-spectral method could even theoretically do better than a spectral method to detect events that are defined by their spectrum, assuming all other aspects are optimized (such as combining data from different channels and threshold setting)
• The CNN network is trained on data from 8 channels but it appears that the compared filter is run on a single channel only. This is explicitly stated for the online SWR detection and presumably, that is the case for the offline as well. This unfair comparison raises the possibility that whatever improved performance the CNN may have may be due to considerably richer input and not due to the CNN model itself. The authors state that a filter on the data from a single channel is the standard, but many studies use various "consensus" heuristics, e.g. in which elevated ripple power is required to be detected on multiple channels simultaneously, which considerably improves detection reliability. Even if this weren't the case, because the CNN learns how to weight each channel, to argue that better performance is due to the nature of the CNN it must be compared to an algorithm that similarly learns to optimize these weights on filtered data across the same number of channels. It is very likely that if this were done, the filter approach would outperform the CNN as its performance with a single channel is comparable.
• Related to the point above, for the proposed CNN model to be a useful tool in the neuroscience field it needs to be amenable to the kind of data and computational resources that are common in the field. As the network requires 8 channels situated in close proximity, the network would not be relevant for numerous studies that use fewer or spaced channels. Further, the filter approach does not require training and it is unclear how generalizable the current CNN model is without additional network training (see below). Together, these points raise the concern that even if the CNN performance is better than a filter approach, it would not be usable by a wide audience.
• A key point is whether the CNN generalizes well across new datasets as the authors suggest. When the model trained on mouse data was applied to rat data from Grosmark and Buzsaki, 2016, precision was low. The authors state that "Hence, we evaluated all False Positive predictions and found that many of them were actually unannotated SWR (839 events), meaning that precision was actually higher". How were these events judged as SWRs? Was the test data reannotated?
• The argument that the network improves with data from multiple experts while the filter does not requires further support. While Fig. 1B shows that the CNN improves performance when the experts' data is combined and the filter doesn't, the final performance on the consolidated data does not appear better in the CNN. This suggests that performance of the CNN when trained on data from single experts was lower to start with. Further, regardless of the point in the bullet point above, the data in Fig. 1E does not convincingly show that the CNN improves while the filter doesn't as there are only 3 data points per comparison and no effect on F1.
• Apart from the points above regarding the ability of the network to detect SWRs, the insight into the nature of SWRs that the authors suggest can be achieved with CNNs is limited. For example, the data in Fig. 3 is a nice analysis of what the components of the CNN learn to identify, but the claim that "some predictions not consistent with the current definition of SWR may identify different forms of population firing and oscillatory activities associated to sharp-waves" is not thoroughly supported. The data in Fig. 4 is convincing in showing that the network better identifies SWRs than non-SWRs, but again the insight is about the network rather than about SWRs. Finally, the application of the model on Neuropixels data also nicely demonstrates the applicability of the model on this kind of data but does not provide new insight regarding SWRs.
In summary, the authors have constructed an elegant new computational tool and convincingly shown its validity in detecting SWRs and applicability to different kinds of data. Unfortunately, I am not convinced that the model convincingly achieves either of its stated goals: exceeding the performance of SWR detection or providing new insights about SWRs as compared to considerably simpler and more accessible current methods.
-

-
