Rapid encoding of task regularities in the human hippocampus guides sensorimotor timing
Curation statements for this article:-
Curated by eLife

Evaluation Summary:
This paper is of interest to scientists interested in the functions of the hippocampus, as well as those in the field of sensorimotor timing. The reported data and findings point towards the possibility that the hippocampus supports specific and generalized learning of short time intervals relevant to behavior. While the conclusions are mostly supported by the evidence, further clarification of methodology as well as additional analyses and discussion would strengthen the authors' conclusions.
(This preprint has been reviewed by eLife. We include the public reviews from the reviewers here; the authors also receive private feedback with suggested changes to the manuscript. The reviewers remained anonymous to the authors.)
This article has been Reviewed by the following groups
Discuss this preprint
Start a discussion What are Sciety discussions?Listed in
- Evaluated articles (eLife)
Abstract
The brain encodes the statistical regularities of the environment in a task-specific yet flexible and generalizable format. Here, we seek to understand this process by bridging two parallel lines of research, one centered on sensorimotor timing, and the other on cognitive mapping in the hippocampal system. By combining functional magnetic resonance imaging (fMRI) with a fast-paced time-to-contact (TTC) estimation task, we found that the hippocampus signaled behavioral feedback received in each trial as well as performance improvements across trials along with reward-processing regions. Critically, it signaled performance improvements independent from the tested intervals, and its activity accounted for the trial-wise regression-to-the-mean biases in TTC estimation. This is in line with the idea that the hippocampus supports the rapid encoding of temporal context even on short time scales in a behavior-dependent manner. Our results emphasize the central role of the hippocampus in statistical learning and position it at the core of a brain-wide network updating sensorimotor representations in real time for flexible behavior.
Article activity feed
-

-

Author Response
Reviewer #1 (Public Review):
The authors evaluate the involvement of the hippocampus in a fast-paced time-to-contact estimation task. They find that the hippocampus is sensitive to feedback received about accuracy on each trial and has activity that tracks behavioral improvement from trial to trial. Its activity is also related to a tendency for time estimation behavior to regress to the mean. This is a novel paradigm to explore hippocampal activity and the results are thus novel and important, but the framing as well as discussion about the meaning of the findings obscures the details of the results or stretches beyond them in many places, as detailed below.
We thank the reviewer for their constructive feedback and were happy to read that s/he considered our approach and results as novel and important. The comments …
Author Response
Reviewer #1 (Public Review):
The authors evaluate the involvement of the hippocampus in a fast-paced time-to-contact estimation task. They find that the hippocampus is sensitive to feedback received about accuracy on each trial and has activity that tracks behavioral improvement from trial to trial. Its activity is also related to a tendency for time estimation behavior to regress to the mean. This is a novel paradigm to explore hippocampal activity and the results are thus novel and important, but the framing as well as discussion about the meaning of the findings obscures the details of the results or stretches beyond them in many places, as detailed below.
We thank the reviewer for their constructive feedback and were happy to read that s/he considered our approach and results as novel and important. The comments led us to conduct new fMRI analyses, to clarify various unclear phrasings regarding our methods, and to carefully assess our framing of the interpretation and scope of our results. Please find our responses to the individual points below.
- Some of the results appear in the posterior hippocampus and others in the anteriorhippocampus. The authors do not motivate predictions for anterior vs. posterior hippocampus, and they do not discuss differences found between these areas in the Discussion. The hippocampus is treated as a unitary structure carrying out learning and updating in this task, but the distinct areas involved motivate a more nuanced picture that acknowledges that the same populations of cells may not be carrying out the various discussed functions.
We thank the reviewer for pointing this out. We split the hippocampus into anterior and posterior sections because prior work suggested a different whole-brain connectivity and function of the two. This was mentioned in the methods section (page 15) in the initial submission but unfortunately not in the main text. Moreover, when discussing the results, we did indeed refer mostly to the hippocampus as a unitary structure for simplicity and readability, and because statements about subcomponents are true for the whole. However, we agree with the reviewer that the differences between anterior and posterior sections are very interesting, and that describing these effects in more detail might help to guide future work more precisely.
In response to the reviewer's comment, we therefore clarified at various locations throughout the manuscript whether the respective results were observed in the posterior or anterior section of the hippocampus, and we extended our discussion to reflect the idea that different functions may be carried out by distinct populations of hippocampal cells. In addition, we also now motivate the split into the different sections better in the main text. We made the following changes.
Page 3: “Second, we demonstrate that anterior hippocampal fMRI activity and functional connectivity tracks the behavioral feedback participants received in each trial, revealing a link between hippocampal processing and timing-task performance.
Page 3: “Fourth, we show that these updating signals in the posterior hippocampus were independent of the specific interval that was tested and activity in the anterior hippocampus reflected the magnitude of the behavioral regression effect in each trial.”
Page 5: “We performed both whole-brain voxel-wise analyses as well as regions-of-interest (ROI) analysis for anterior and posterior hippocampus separately, for which prior work suggested functional differences with respect to their contributions to memory-guided behavior (Poppenk et al., 2013, Strange et al. 2014).”
Page 9: “Because anterior and posterior sections of the hippocampus differ in whole-brain connectivity as well as in their contributions to memory-guided behavior (Strange et al. 2014), we analyzed the two sections separately. “
Page 9: “We found that anterior hippocampal activity as well as functional connectivity reflected the feedback participants received during this task, and its activity followed the performance improvements in a temporal-context-dependent manner. Its activity reflected trial-wise behavioral biases towards the mean of the sampled intervals, and activity in the posterior hippocampus signaled sensorimotor updating independent of the specific intervals tested.”
Page 10: “Intriguingly, the mechanisms at play may build on similar temporal coding principles as those discussed for motor timing (Yin & Troger, 2011; Eichenbaum, 2014; Howard, 2017; Palombo & Verfaellie, 2017; Nobre & van Ede, 2018; Paton & Buonomano, 2018; Bellmund et al., 2020, 2021; Shikano et al., 2021; Shimbo et al., 2021), with differential contributions of the anterior and posterior hippocampus. Note that our observation of distinct activity modulations in the anterior and posterior hippocampus suggests that the functions and coding principles discussed here may be mediated by at least partially distinct populations of hippocampal cells.”
Page 11: Interestingly, we observed that functional connectivity of the anterior hippocampus scaled negatively (Fig. 2C) with feedback valence [...]
- Hippocampal activity is stronger for smaller errors, which makes the interpretationmore complex than the authors acknowledge. If the hippocampus is updating sensorimotor representations, why would its activity be lower when more updating is needed?
Indeed, we found that absolute (univariate) activity of the hippocampus scaled with feedback valence, the inverse of error (Fig. 2A). We see multiple possibilities for why this might be the case, and we discussed some of them in a dedicated discussion section (“The role of feedback in timed motor actions”). For example, prior work showed that hippocampal activity reflects behavioral feedback also in other tasks, which has been linked to learning (e.g. Schönberg et al., 2007; Cohen & Ranganath, 2007; Shohamy & Wagner, 2008; Foerde & Shohamy, 2011; Wimmer et al., 2012). In our understanding, sensorimotor updating is a form of ‘learning’ in an immediate and behaviorally adaptive manner, and we therefore consider our results well consistent with this earlier work. We agree with the reviewer that in principle activity should be stronger if there was stronger sensorimotor updating, but we acknowledge that this intuition builds on an assumption about the relationship between hippocampal neural activity and the BOLD signal, which is not entirely clear. For example, prior work revealed spatially informative negative BOLD responses in the hippocampus as a function of visual stimulation (e.g. Szinte & Knapen 2020), and the effects of inhibitory activity - a leading motif in the hippocampal circuitry - on fMRI data are not fully understood. This raises the possibility that the feedback modulation we observed might also involve negative BOLD responses, which would then translate to the observed negative correlation between feedback valence and the hippocampal fMRI signal, even if the magnitude of the underlying updating mechanism was positively correlated with error. This complicates the interpretation of the direction of the effect, which is why we chose to avoid making strong conclusions about it in our manuscript. Instead, we tried discussing our results in a way that was agnostic to the direction of the feedback modulation. Importantly, hippocampal connectivity with other regions did scale positively with error (Fig. 2B), which we again discussed in the dedicated discussion section.
In response to the reviewer’s comment, we revisited this section of our manuscript and felt the latter result deserved a better discussion. We therefore took this opportunity to extend our discussion of the connectivity results (including their relationship to the univariate-activity results as well as the direction of these effects), all while still avoiding strong conclusions about directionality. Following changes were made to the manuscript.
Page 11: Interestingly, we observed that functional connectivity of the anterior hippocampus scaled negatively (Fig. 2C) with feedback valence, unlike its absolute activity, which scaled positively with feedback valence (Fig. 2A,B), suggesting that the two measures may be sensitive to related but distinct processes.
Page 11: Such network-wide receptive-field re-scaling likely builds on a re-weighting of functional connections between neurons and regions, which may explain why anterior hippocampal connectivity correlated negatively with feedback valence in our data. Larger errors may have led to stronger re-scaling, which may be grounded in a corresponding change in functional connectivity.
- Some tests were one-tailed without justification, which reduces confidence in the robustness of the results.
We thank the reviewer for pointing us to the fact that our choice of statistical tests was not always clear in the manuscript. In the analysis the reviewer is referring to, we predicted that stronger sensorimotor updating should lead to stronger activity as well as larger behavioral improvements across the respective trials. This is because a stronger update should translate to a more accurate “internal model” of the task and therefore to a better performance. We tested this one-sided hypothesis using the appropriate test statistic (contrasting trials in which behavioral performance did improve versus trials in which it did not improve), but we did not motivate our reasoning well enough in the manuscript. The revised manuscript therefore includes the two new statements shown below to motivate our choice of test statistic more clearly.
Page 7: [...] we contrasted trials in which participants had improved versus the ones in which they had not improved or got worse (see methods for details). Because stronger sensorimotor updating should lead to larger performance improvements, we predicted to find stronger activity for improvements vs. no improvements in these tests (one-tailed hypothesis).
Page 18: These two regressors reflect the tests for target-TTC-independent and target-TTC-specific updating, respectively. Because we predicted to find stronger activity for improvements vs. no improvements in behavioral performance, we here performed one-tailed statistical tests, consistent with the direction of this hypothesis. Improvement in performance was defined as receiving feedback of higher valence than in the corresponding previous trial.
- The introduction motivates the novelty of this study based on the idea that thehippocampus has traditionally been thought to be involved in memory at the scale of days and weeks. However, as is partially acknowledged later in the Discussion, there is an enormous literature on hippocampal involvement in memory at a much shorter timescale (on the order of seconds). The novelty of this study is not in the timescale as much as in the sensorimotor nature of the task.
We thank the reviewer for this helpful suggestion. We agree that a key part of the novelty of this study is the use of the task that is typically used to study sensorimotor integration and timing rather than hippocampal processing, along with the new insights this task enabled about the role of the hippocampus in sensorimotor updating. As mentioned in the discussion, we also agree with the reviewer that there is prior literature linking hippocampal activity to mnemonic processing on short time scales. We therefore rephrased the corresponding section in the introduction to put more weight on the sensorimotor nature of our task instead of the time scales.
Note that the new statement still includes the time scale of the effects, but that it is less at the center of the argument anymore. We chose to keep it in because we do think that the majority of studies on hippocampal-dependent memory functions focus on longer time scales than our study does, and we expect that many readers will be surprised about the immediacy of how hippocampal activity relates to ongoing behavioral performance (on ultrashort time scales).
We changed the introduction to the following.
Page 2: Here, we approach this question with a new perspective by converging two parallel lines of research centered on sensorimotor timing and hippocampal-dependent cognitive mapping. Specifically, we test how the human hippocampus, an area often implicated in episodic-memory formation (Schiller et al., 2015; Eichenbaum, 2017), may support the flexible updating of sensorimotor representations in real time and in concert with other regions. Importantly, the hippocampus is not traditionally thought to support sensorimotor functions, and its contributions to memory formation are typically discussed for longer time scales (hours, days, weeks). Here, however, we characterize in detail the relationship between hippocampal activity and real-time behavioral performance in a fast-paced timing task, which is traditionally believed to be hippocampal-independent. We propose that the capacity of the hippocampus to encode statistical regularities of our environment (Doeller et al. 2005, Shapiro et al. 2017, Behrens et al., 2018; Momennejad, 2020; Whittington et al., 2020) situates it at the core of a brain-wide network balancing specificity vs. regularization in real time as the relevant behavior is performed.
- The authors used three different regressors for the three feedback levels, asopposed to a parametric regressor indexing the level of feedback. The predictions are parametric, so a parametric regressor would be a better match, and would allow for the use of all the medium-accuracy data.
The reviewer raises a good point that overlaps with question 3 by reviewer 2. In the current analysis, we model the three feedback levels with three independent regressors (high, medium, low accuracy). We then contrast high vs. low accuracy feedback, obtaining the results shown in Fig. 2AB. The beta estimates obtained for medium-accuracy feedback are being ignored in this contrast. Following the reviewer’s feedback, we therefore re-run the model, this time modeling all three feedback levels in one parametric regressor. All other regressors in the model stayed the same. Instead of contrasting high vs. low accuracy feedback, we then performed voxel-wise t-tests on the beta estimates obtained for the parametric feedback regressor.
The results we observed were highly consistent across the two analyses, and all conclusions presented in the initial manuscript remain unchanged. While the exact t-scores differ slightly, we replicated the effects for all clusters on the voxel-wise map (on whole-brain FWE-corrected levels) as well as for the regions-of-interest analysis for anterior and posterior hippocampus. These results are presented in a new Supplementary Figure 3C.
Note that the new Supplementary Figure 3B shows another related new analyses we conducted in response to question 4 of reviewer 2. Here, we re-ran the initial analysis with three feedback regressors, but without modeling the inter-trial interval (ITI) and the inter-session interval (ISI, i.e. the breaks participants took) to avoid model over-specification. Again, we replicated the results for all clusters and the ROI analysis, showing that the initial results we presented are robust.
The following additions were made to the manuscript.
Page 5: Note that these results were robust even when fewer nuisance regressors were included to control for model over-specification (Fig. S3B; two-tailed one-sample t tests: anterior HPC, t(33) = -3.65, p = 8.9x10-4, pfwe = 0.002, d=-0.63, CI: [-1.01, -0.26]; posterior HPC, t(33) = -1.43, p = 0.161, pfwe = 0.322, d=-0.25, CI: [-0.59, 0.10]), and when all three feedback levels were modeled with one parametric regressors (Fig. S3C; two-tailed one-sample t tests: anterior HPC, t(33) = -3.59, p = 0.002, pfwe = 0.005, d=-0.56, CI: [-0.93, -0.20]; posterior HPC, t(33) = -0.99, p = 0.329, pfwe = 0.659, d=-0.17, CI: [-0.51, 0.17]). Further, there was no systematic relationship between subsequent trials on a behavioral level [...]
Page 17: Moreover, instead of modeling the three feedback levels with three independent regressors, we repeated the analysis modeling the three feedback levels as one parametric regressor with three levels. All other regressors remained unchanged, and the model included the regressors for ITIs and ISIs. We then conducted t-tests implemented in SPM12 using the beta estimates obtained for the parametric feedback regressor (Fig. 2C). Compared to the initial analyses presented above, this has the advantage that medium-accuracy feedback trials are considered for the statistics as well.
- The authors claim that the results support the idea that the hippocampus is findingan "optimal trade-off between specificity and regularization". This seems overly speculative given the results presented.
We understand the reviewer's skepticism about this statement and agree that the manuscript does not show that the hippocampus is finding the trade-off between specificity and regularization. However, this is also not exactly what the manuscript claims. Instead, it suggests that the hippocampus “may contribute” to solving this trade-off (page 3) as part of a “brain-wide network“ (pages 2,3,9,12). We also state that “Our [...] results suggest that this trade-off [...] is governed by many regions, updating different types of task information in parallel” (Page 11). To us, these phrasings are not equivalent, because we do not think that the role of the hippocampus in sensorimotor updating (or in any process really) can be understood independently from the rest of the brain. We do however think that our results are in line with the idea that the hippocampus contributes to solving this trade-off, and that this is exciting and surprising given the sensorimotor nature of our task, the ultrashort time scale of the underlying process, and the relationship to behavioral performance. We tried expressing that some of the points discussed remain speculation, but it seems that we were not always successful in doing so in the initial submission. We apologize for the misunderstanding, adapted corresponding statements in the manuscript, and we express even more carefully that these ideas are speculation.
Following changes were made to the introduction and discussion.
Page 2: Here, we approach this question with a new perspective by converging two parallel lines of research centered on sensorimotor timing and hippocampal-dependent cognitive mapping. Specifically, we test how the human hippocampus, an area often implicated in episodic-memory formation (Schiller et al., 2015; Eichenbaum, 2017), may support the flexible updating of sensorimotor representations in real time and in concert with other regions.
Page 12: Because hippocampal activity (Julian & Doeller, 2020) and the regression effect (Jazayeri & Shadlen, 2010) were previously linked to the encoding of (temporal) context, we reasoned that hippocampal activity should also be related to the regression effect directly. This may explain why hippocampal activity reflected the magnitude of the regression effect as well as behavioral improvements independently from TTC, and why it reflected feedback, which informed the updating of the internal prior.
Page 12: This is in line with our behavioral results, showing that TTC-task performance became more optimal in the face of both of these two objectives. Over time, behavioral responses clustered more closely between the diagonal and the average line in the behavioral response profile (Fig. 1B, S1G), and the TTC error decreased over time. While different participants approached these optimal performance levels from different directions, either starting with good performance or strong regularization, the group approached overall optimal performance levels over the course of the experiment.
Page 13: This is in line with the notion that the hippocampus [...] supports finding an optimal trade off between specificity and regularization along with other regions. [...] Our results show that the hippocampus supports rapid and feedback-dependent updating of sensorimotor representations, suggesting that it is a central component of a brain-wide network balancing task specificity vs. regularization for flexible behavior in humans.
Note that in response to comment 1 by reviewer 2, the revised manuscript now reports the results of additional behavioral analyses that support the notion that participants find an optimal trade-off between specificity and regularization over time (independent of whether the hippocampus was involved or not).
- The authors find that hippocampal activity is related to behavioral improvement fromthe prior trial. This seems to be a simple learning effect (participants can learn plenty about this task from a prior trial that does not have the exact same timing as the current trial) but is interpreted as sensitivity to temporal context. The temporal context framing seems too far removed from the analyses performed.
We agree with the reviewer that our observation that hippocampal activity reflects TTC-independent behavioral improvements across trials could have multiple explanations. Critically, i) one of them is that the hippocampus encodes temporal context, ii) it is only one of multiple observations that we build our interpretation on, and iii) our interpretation builds on multiple earlier reports
Interval estimates regress toward the mean of the sampled intervals, an effect that is often referred to as the “regression effect”. This effect, which we observed in our data too (Fig. 1B), has been proposed to reflect the encoding of temporal context (e.g. Jazayeri & Shadlen 2010). Moreover, there is a large body of literature on how the hippocampus may support the encoding of spatial and temporal context (e.g. see Bellmund, Polti & Doeller 2020 for review).
Because both hippocampal activity and the regression effect were linked to the encoding of (temporal) context, we reasoned that hippocampal activity should also be related to the regression effect directly. If so, one would expect that hippocampal activity should reflect behavioral improvements independently from TTC, it should reflect the magnitude of the regression effect, and it should generally reflect feedback, because it is the feedback that informs the updating of the internal prior.
All three observations may have independent explanations indeed, but they are all also in line with the idea that the hippocampus does encode temporal context and that this explains the relationship between hippocampal activity and the regression effect. It therefore reflects a sparse and reasonable explanation in our opinion, even though it necessarily remains an interpretation. Of course, we want to be clear on what our results are and what our interpretations are.
In response to the reviewer’s comment, we therefore toned down two of the statements that mention temporal context in the manuscript, and we removed an overly speculative statement from the result section. In addition, the discussion now describes more clearly how our results are in line with this interpretation.
Abstract: This is in line with the idea that the hippocampus supports the rapid encoding of temporal context even on short time scales in a behavior-dependent manner.
Page 13: This is in line with the notion that the hippocampus encodes temporal context in a behavior-dependent manner, and that it supports finding an optimal trade off between specificity and regularization along with other regions.
Page 12: Because hippocampal activity (Julian & Doeller, 2020) and the regression effect (Jazayeri & Shadlen, 2010) were previously linked to the encoding of (temporal) context, we reasoned that hippocampal activity should also be related to the regression effect directly. This may explain why hippocampal activity reflected the magnitude of the regression effect as well as behavioral improvements independently from TTC, and why it reflected feedback, which informed the updating of the internal prior.
The following statement was removed, overlapping with comment 2 by Reviewer 3:
Instead, these results are consistent with the notion that hippocampal activity signals the updating of task-relevant sensorimotor representations in real-time.
- I am not sure the term "extraction of statistical regularities" is appropriate. The termis typically used for more complex forms of statistical relationships.
We agree with the reviewer that this expression may be interpreted differently by different readers and are grateful to be pointed to this fact. We therefore removed it and instead added the following (hopefully less ambiguous) statement to the manuscript.
Page 9: This study investigated how the human brain flexibly updates sensorimotor representations in a feedback-dependent manner in the service of timing behavior.
Reviewer #2 (Public Review):
The authors conducted a study involving functional magnetic resonance imaging and a time-to-contact estimation paradigm to investigate the contribution of the human hippocampus (HPC) to sensorimotor timing, with a particular focus on the involvement of this structure in specific vs. generalized learning. Suggestive of the former, it was found that HPC activity reflected time interval-specific improvements in performance while in support of the latter, HPC activity was also found to signal improvements in performance, which were not specific to the individual time intervals tested. Based on these findings, the authors suggest that the human HPC plays a key role in the statistical learning of temporal information as required in sensorimotor behaviour.
By considering two established functions of the HPC (i.e., temporal memory and generalization) in the context of a domain that is not typically associated with this structure (i.e., sensorimotor timing), this study is potentially important, offering novel insight into the involvement of the HPC in everyday behaviour. There is much to like about this submission: the manuscript is clearly written and well-crafted, the paradigm and analyses are well thought out and creative, the methodology is generally sound, and the reported findings push us to consider HPC function from a fresh perspective. A relative weakness of the paper is that it is not entirely clear to what extent the data, at least as currently reported, reflects the involvement of the HPC in specific and generalized learning. Since the authors' conclusions centre around this observation, clarifying this issue is, in my opinion, of primary importance.
We thank the reviewer for these positive and extremely helpful comments, which we will address in detail below. In response to these comments, the revised manuscript clarifies why the observed performance improvements are not at odds with the idea that an optimal trade-off between specificity and regularization is found, and how the time course of learning relates to those reported in previous literature. In addition, we conducted two new fMRI analyses, ensuring that our conclusions remain unchanged even if feedback is modeled with one parametric regressor, and if the number or nuisance regressors is reduced to control for overparameterization of the model. Please find our responses underneath each individual point below.
- Throughout the manuscript, the authors discuss the trade-off between specific and generalized learning, and point towards Figure S1D as evidence for this (i.e., participants with higher TTC accuracy exhibited a weaker regression effect). What appears to be slightly at odds with this, however, is the observation that the deviation from true TTC decreased with time (Fig S1F) as the regression line slope approached 0.5 (Fig S1E) - one would have perhaps expected the opposite i.e., for deviation from true TTC to increase as generalization increases. To gain further insight into this, it would be helpful to see the deviation from true TTC plotted for each of the four TTC intervals separately and as a signed percentage of the target TTC interval (i.e., (+) or (-) deviation) rather than the absolute value.
We thank the reviewer for raising this important question and for the opportunity to elaborate on the relationship between the TTC error and the magnitude of the regression effect in behavior. Indeed, we see that the regression slopes approach 0.5 and that the TTC error decreases over the course of the experiment. We do not think that these two observations are at odds with each other for the following reasons:
First, while the reviewer is correct in pointing out that the deviation from the TTC should increase as “generalization increases”, that is not what we found. It was not the magnitude of the regularization per se that increased over time, but the overall task performance became more optimal in the face of both objectives: specificity and generalization. This optimum is at a regression-line slope of 0.5. Generalization (or regularization how we refer to it in the present manuscript), therefore did not increase per se on group level.
Second, the regression slopes approached 0.5 on the group-level, but the individual participants approached this level from different directions: Some of them started with a slope value close to 1 (high accuracy), whereas others started with a slope value close to 0 (near full regression to the mean). Irrespective of which slope value they started with, over time, they got closer to 0.5 (Rebuttal Figure 1A). This can also be seen in the fact that the group-level standard deviation in regression slopes becomes smaller over the course of the experiment (Rebuttal Figure 1B, SFig 1G). It is therefore not generally the case that the regression effect becomes stronger over time, but that it becomes more optimal for longer-term behavioral performance, which is then also reflected in an overall decrease in TTC error. Please see our response to the reviewer’s second comment for more discussion on this.
Third, the development of task performance is a function of two behavioral factors: a) the accuracy and b) the precision in TTC estimation. Accuracy describes how similar the participant’s TTC estimates were to the true TTC, whereas precision describes how similar the participant’s TTC estimates were relative to each other (across trials). Our results are a reflection of the fact that participants became both more accurate over time on average, but also more precise. To demonstrate this point visually, we now plotted the Precision and the Accuracy for the 8 task segments below (Rebuttal Figure 1C, SFig 1H), showing that both measures increased as the time progressed and more trials were performed. This was the case for all target durations.
In response to the reviewer’s comment, we clarified in the main text that these findings are not at odds with each other. Furthermore, we made clear that regularization per se did not increase over time on group level. We added additional supporting figures to the supplementary material to make this point. Note that in our view, these new analyses and changes more directly address the overall question the reviewer raised than the figure that was suggested, which is why we prioritized those in the manuscript.
However, we appreciated the suggestion a lot and added the corresponding figure for the sake of completeness.
Following additions were made.
Page 5: In support of this, participants' regression slopes converged over time towards the optimal value of 0.5, i.e. the slope value between veridical performance and the grand mean (Fig. S1F; linear mixed-effects model with task segment as a predictor and participants as the error term, F(1) = 8.172, p = 0.005, ε2=0.08, CI: [0.01, 0.18]), and participants' slope values became more similar (Fig. S1G; linear regression with task segment as predictor, F(1) = 6.283, p = 0.046, ε2 = 0.43, CI: [0, 1]). Consequently, this also led to an improvement in task performance over time on group level (i.e. task accuracy and precision increased (Fig. S1I), and the relationship between accuracy and precision became stronger (Fig. S1H), linear mixed-effect model results for accuracy: F(1) = 15.127, p = 1.3x10-4, ε2=0.06, CI: [0.02, 0.11], precision: F(1) = 20.189, p = 6.1x10-5, ε2 = 0.32, CI: [0.13, 1]), accuracy-precision relationship: F(1) = 8.288, p =0.036, ε2 = 0.56, CI: [0, 1], see methods for model details).
Page 12: This suggests that different regions encode distinct task regularities in parallel to form optimal sensorimotor representations to balance specificity and regularization. This is in line with our behavioral results, showing that TTC-task performance became more optimal in the face of both of these two objectives. Over time, behavioral responses clustered more closely between the diagonal and the average line in the behavioral response profile (Fig. 1B, S1G), and the TTC error decreased over time. While different participants approached these optimal performance levels from different directions, either starting with good performance or strong regularization, the group approached overall optimal performance levels over the course of the experiment.
Page 15: We also corroborated this effect by measuring the dispersion of slope values between participants across task segments using a linear regression model with task segment as a predictor and the standard deviation of slope values across participants as the dependent variable (Fig. S1G). As a measure of behavioral performance, we computed two variables for each target-TTC level: sensorimotor timing accuracy, defined as the absolute difference in estimated and true TTC, and sensorimotor timing precision, defined as coefficient of variation (standard deviation of estimated TTCs divided by the average estimated TTC). To study the interaction between these two variables for each target TTC over time, we first normalized accuracy by the average estimated TTC in order to make both variables comparable. We then used a linear mixed-effects model with precision as the dependent variable, task segment and normalized accuracy as predictors and target TTC as the error term. In addition, we tested whether accuracy and precision increased over the course of the experiment using separate linear mixed-effects models with task segment as predictor and participants as the error term.
- Generalization relies on prior experience and can be relatively slow to develop as is the case with statistical learning. In Jazayeri and Shadlen (2010), for instance, learning a prior distribution of 11-time intervals demarcated by two briefly flashed cues (compared to 4 intervals associated with 24 possible movement trajectories in the current study) required ~500 trials. I find it somewhat surprising, therefore, that the regression line slope was already relatively close to 0.5 in the very first segment of the task. To what extent did the participants have exposure to the task and the target intervals prior to entering the scanner?
We thank the reviewer for raising the important question about the time course of learning in our task and how our results relate to prior work on this issue. Addressing the specific reviewer question first, participants practiced the task for 2-3 minutes prior to scanning. During the practice, they were not specifically instructed to perform the task as well as they could nor to encode the intervals, but rather to familiarize themselves with the general experimental setup and to ask potential questions outside the MRI machine. While they might have indeed started encoding the prior distribution of intervals during the practice already, we have no way of knowing, and we expect the contribution of this practice on the time course of learning during scanning to be negligible (for the reasons outlined above).
However, in addition to the specific question the reviewer asked, we feel that the comment raises two more general points: 1) How long does it take to learn the prior distribution of a set of intervals as a function of the number of intervals tested, and 2) Why are the learning slopes we report quite shallow already in the beginning of the scan?
Regarding (1), we are not aware of published reports that answer this question directly, and we expect that this will depend on the task that is used. Regarding the comparison to Jazayeri & Shadlen (2010), we believe the learning time course is difficult to compare between our study and theirs. As the reviewer mentioned, our study featured only 4 intervals compared to 11 in their work, based on which we would expect much faster learning in our task than in theirs. We did indeed sample 24 movement directions, but these were irrelevant in terms of learning the interval distribution. Moreover, unlike Jazayeri & Shadlen (2010), our task featured moving stimuli, which may have added additional sensory, motor and proprioceptive information in our study which the participants of the prior study could not rely on.
Regarding (2), and overlapping with the reviewer’s previous comment, the average learning slope in our study is indeed close to 0.5 already in the first task segment, but we would like to highlight that this is a group-level measure. The learning slopes of some subjects were closer to 1 (i.e. the diagonal in Fig 1B), and the one of others was closer to 0 (i.e. the mean) in the beginning of the experiment. The median slope was close to 0.65. Importantly, the slopes of most participants still approached 0.5 in the course of the experiment, and so did even the group-level slope the reviewer is referring to. This also means that participants’ slopes became more similar in the course of the experiment, and they approached 0.5, which we think reflects the optimal trade-off between regressing towards the mean and regressing towards the diagonal (in the data shown in Fig. 1B). This convergence onto the optimal trade-off value can be seen in many measures, including the mean slope (Rebuttal Figure 1A, SFig 1F), the standard deviation in slopes (Rebuttal Figure 1B, SFig 1G) as well as the Precision vs. Accuracy tradeoff (Rebuttal Figure 1C, SFig 1H). We therefore think that our results are well in line with prior literature, even though a direct comparison remains difficult due to differences in the task.
In response to the reviewer’s comment, and related to their first comment, we made the following addition to the discussion section.
Page 12: This suggests that different regions encode distinct task regularities in parallel to form optimal sensorimotor representations to balance specificity and regularization. This is well in line with our behavioral results, showing that TTC-task performance became more optimal in the face of both of these two objectives. Over time, behavioral responses clustered more closely between the diagonal and the average line in the behavioral response profile (Fig. 1B, S1G), and the TTC error decreased over time. While different participants approached these optimal performance levels from different directions, either starting with good performance or strong regularization, the group approached overall optimal performance levels over the course of the experiment.
- I am curious to know whether differences between high-accuracy andmedium-accuracy feedback as well as between medium-accuracy and low-accuracy feedback predicted hippocampal activity in the first GLM analysis (middle page 5). Currently, the authors only present the findings for the contrast between high-accuracy and low-accuracy feedback. Examining all feedback levels may provide additional insight into the nature of hippocampal involvement and is perhaps more consistent with the subsequent GLM analysis (bottom page 6) in which, according to my understanding, all improvements across subsequent trials were considered (i.e., from low-accuracy to medium-accuracy; medium-accuracy to high-accuracy; as well as low-accuracy to high-accuracy).
We thank the reviewer for this thoughtful question, which relates to questions 5 by reviewer 1. The reviewer is correct that the contrast shown in Fig 2 does not consider the medium-accuracy feedback levels, and that the model in itself is slightly different from the one used in the subsequent analysis presented in Fig. 3. To reply to this comment as well as to a related one by reviewer 1 together, we therefore repeated the full analysis while modeling the three feedback levels in one parametric regressor, which includes the medium-accuracy feedback trials, and is consistent with the analysis shown in Fig. 3. The results of this new analysis are presented in the new Supplementary Fig. 3B.
In short, the model included one parametric regressor with three levels reflecting the three types of feedback, and all nuisance regressors remained unchanged. Instead of contrasting high vs. low accuracy feedback, we then performed voxel-wise t-tests on the beta estimates obtained for the parametric feedback regressor. We found that our results presented initially were very robust: Both the observed clusters in the voxel-wise analysis (on whole-brain FWE-corrected levels) as well as the ROI results replicated across the two analyses, and our conclusions therefore remain unchanged.
We made multiple textual additions to the manuscript to include this new analysis, and we present the results of the analysis including a direct comparison to our initial results in the new Supplementary Fig. 3. Following textual additions were.
Page 5: Note that these results were robust even when fewer nuisance regressors were included to control for model over-specification (Fig. S3B; two-tailed one-sample t tests: anterior HPC, t(33) = -3.65, p = 8.9x10-4, pfwe = 0.002, d=-0.63, CI: [-1.01, -0.26]; posterior HPC, t(33) = -1.43, p = 0.161, pfwe = 0.322, d=-0.25, CI: [-0.59, 0.10]), and when all three feedback levels were modeled with one parametric regressors (Fig. S3C; two-tailed one-sample t tests: anterior HPC, t(33) = -3.59, p = 0.002, pfwe = 0.005, d=-0.56, CI: [-0.93, -0.20]; posterior HPC, t(33) = -0.99, p = 0.329, pfwe = 0.659, d=-0.17, CI: [-0.51, 0.17]). Further, there was no systematic relationship between subsequent trials on a behavioral level [...]
Page 17: Moreover, instead of modeling the three feedback levels with three independent regressors, we repeated the analysis modeling the three feedback levels as one parametric regressor with three levels. All other regressors remained unchanged, and the model included the regressors for ITIs and ISIs. We then conducted t-tests implemented in SPM12 using thebeta estimates obtained for the parametric feedback regressor (Fig. S2C). Compared to the initial analyses presented above, this has the advantage that medium-accuracy feedback trials are considered for the statistics as well.
- The authors modeled the inter-trial intervals and periods of rest in their univariateGLMs. This approach of modelling all 'down time' can lead to model over-specification and inaccurate parameter estimation (e.g. Pernet, 2014). A comment on this approach as well as consideration of not modelling the inter-trial intervals would be useful.
This is an important issue that we did not address in our initial manuscript. We are aware and agree with the reviewer’s general concern about model over-specification, which can be a big problem in regression as it leads to biased estimates. We did examine whether our model was overspecified before running it, but we did not report a formal test of it in the manuscript. We are grateful to be given the opportunity to do so now.
In response to the reviewer’s comment, we repeated the full analysis shown in Fig. 2 while excluding the nuisance regressors for inter-trial intervals (ISI) and breaks (or inter-session intervals, ISI). All other regressors and analysis steps stayed unchanged relative to the one reported in Fig. 2. The new results are presented in a new Supplementary Figure 3B.
Like for our previous analysis, we again see that the results we initially presented were extremely robust even on whole-brain FWE corrected levels, as well as on ROI level. Our conclusions therefore remain unchanged, and the results we presented initially are not affected by potential model overspecification. In addition to the new Supplementary Figure 3B, we made multiple textual changes to the manuscript to describe this new analysis and its implications. Note that we used the same nuisance regressors in all other GLM analyses too, meaning that it is also very unlikely that model overspecification affects any of the other results presented. We thank the reviewer for suggesting this analysis, and we feel including it in the manuscript has further strengthened the points we initially made.
Following additions were made to the manuscript.
Page 16: The GLM included three boxcar regressors modeling the feedback levels, one for ITIs, one for button presses and one for periods of rest (inter-session interval, ISI) [...]
Page 16: ITIs and ISIs were modeled to reduce task-unrelated noise, but to ensure that this did not lead to over-specification of the above-described GLM, we repeated the full analysis without modeling the two. All other regressors including the main feedback regressors of interest remained unchanged, and we repeated both the voxel-wise and ROI-wise statistical tests as described above (Fig. S2B).
Page 17: Note that these results were robust even when fewer nuisance regressors were included to control for model over-specification (Fig. S3B; two-tailed one-sample t tests: anterior HPC, t(33) = -3.65, p = 8.9x10-4, pfwe = 0.002, d=-0.63, CI: [-1.01, -0.26]; posterior HPC, t(33) = -1.43, p = 0.161, pfwe = 0.322, d=-0.25, CI: [-0.59, 0.10]), and when all three feedback levels were modeled with one parametric regressors (Fig. S3C; two-tailed one-sample t tests: anterior HPC, t(33) = -3.59, p = 0.002, pfwe = 0.005, d=-0.56, CI: [-0.93, -0.20]; posterior HPC, t(33) = -0.99, p = 0.329, pfwe = 0.659, d=-0.17, CI: [-0.51, 0.17]). Further, there was no systematic relationship between subsequent trials on a behavioral level [...]
Reviewer #3 (Public Review):
This paper reports the results of an interesting fMRI study examining the neural correlates of time estimation with an elegant design and a sensorimotor timing task. Results show that hippocampal activity and connectivity are modulated by performance on the task as well as the valence of the feedback provided. This study addresses a very important question in the field which relates to the function of the hippocampus in sensorimotor timing. However, a lack of clarity in the description of the MRI results (and associated methods) currently prevents the evaluation of the results and the interpretations made by the authors. Specifically, the model testing for timing-specific/timing-independent effects is questionable and needs to be clarified. In the current form, several conclusions appear to not be fully supported by the data.
We thank the reviewer for pointing us to many methodological points that needed clarification. We apologize for the confusion about our methods, which we clarify in the revised manuscript. Please find our responses to the individual points below.
Major points
Some methodological points lack clarity which makes it difficult to evaluate the results and the interpretation of the data.
We really appreciate the many constructive comments below. We feel that clarifying these points improved our manuscript immensely.
- It is unclear how the 3 levels of accuracy and feedback (high, medium, and lowperformance) were computed. Please provide the performance range used for this classification. Was this adjusted to the participants' performance?
The formula that describes how the response window was computed for the different speed levels was reported in the methods section of the original manuscript on page 13. It reads as follows:
“The following formula was used to scale the response window width: d ± ((k ∗ d)/2) where d is the target TTC and k is a constant proportional to 0.3 and 0.6 for high and medium accuracy, respectively.“
In response to the reviewer’s comment, we now additionally report the exact ranges of the different response windows in a new Supplementary Table 1 and refer to it in the Methods section as follows.
Page 10: To calibrate performance feedback across different TTC durations, the precise response window widths of each feedback level scaled with the speed of the fixation target (Table S1).
- The description of the MRI results lacks details. It is not always clear in the resultssection which models were used and whether parametric modulators were included or not in the model. This makes the results section difficult to follow. For example,
a) Figure 2: According to the description in the text, it appears that panels A and B report the results of a model with 3 regressors, ie one for each accuracy/feedback level (high, medium, low) without parametric modulators included. However, the figure legend for panel B mentions a parametric modulator suggesting that feedback was modelled for each trial as a parametric modulator. The distinction between these 2 models must be clarified in the result section.
We thank the reviewer very much for spotting this discrepancy. Indeed, Figure 2 shows the results obtained for a GLM in which we modeled the three feedback levels with separate regressors, not with one parametric regressor. Instead, the latter was the case for Figure 3. We apologize for the confusion and corrected the description in the figure caption, which now reads as follows. The description in the main text and the methods remain unchanged.
Caption Fig. 2: We plot the beta estimates obtained for the contrast between high vs. low feedback.
Moreover, note that in response to comment 5 by reviewer 1 and comment 3 by reviewer 2, the revised manuscript now additionally reports the results obtained for the parametric regressor in the new Supplementary Figure 3C. All conclusions remain unchanged.
Additionally, it is unclear how Figure 2A supports the following statement: "Moreover, the voxel-wise analysis revealed similar feedback-related activity in the thalamus and the striatum (Fig. 2A), and in the hippocampus when the feedback of the current trial was modeled (Fig. S3)." This is confusing as Figure 2A reports an opposite pattern of results between the striatum/thalamus and the hippocampus. It appears that the statement highlighted above is supported by results from a model including current trial feedback as a parametric modulator (reported in Figure S3).
We agree with the reviewer that our result description was confusing and changed it. It now reads as follows.
Page 5: Moreover, the voxel-wise analysis revealed feedback-related activity also in the thalamus and the striatum (Fig. 2A) [...]
Also, note that it is unclear from Figure 2A what is the direction of the contrast highlighting the hippocampal cluster (high vs. low according to the text but the figure shows negative values in the hippocampus and positive values in the thalamus). These discrepancies need to be addressed and the models used to support the statements made in the results sections need to be explicitly described.
The description of the contrast is correct. Negative values indicate smaller errors and therefore better feedback, which is mentioned in the caption of Fig. 2 as follows:
“Negative values indicate that smaller errors, and higher-accuracy feedback, led to stronger activity.”
Note that the timing error determined the feedback, and that we predicted stronger updating and therefore stronger activity for larger errors (similar to a prediction error). We found the opposite. We mention the reasoning behind this analysis at various locations in the manuscript e.g. when talking about the connectivity analysis:
“We reasoned that larger timing errors and therefore low-accuracy feedback would result in stronger updating compared to smaller timing errors and high-accuracy feedback”
In response to the reviewer’s remark, we clarified this further by adding the following statement to the result section.
Page 5: “Using a mass-univariate general linear model (GLM), we modeled the three feedback levels with one regressor each plus additional nuisance regressors (see methods for details). The three feedback levels (high, medium and low accuracy) corresponded to small, medium and large timing errors, respectively. We then contrasted the beta weights estimated for high-accuracy vs. low-accuracy feedback and examined the effects on group-level averaged across runs.”
b) Connectivity analyses: It is also unclear here which model was used in the PPIanalyses presented in Figure 2. As it appears that the seed region was extracted from a high vs. low contrast (without modulators), the PPI should be built using the same model. I assume this was the case as the authors mentioned "These co-fluctuations were stronger when participants performed poorly in the previous trial and therefore when they received low-accuracy feedback." if this refers to low vs. high contrast. Please clarify.
Yes, the PPI model was built using the same model. We clarified this in the methods section by adding the following statement to the PPI description.
Page 17: “The PPI model was built using the same model that revealed the main effects used to define the HPC sphere “
Yes, the reviewer is correct in thinking that the contrast shows the difference between low vs. high-accuracy feedback. We clarified this in the main text as well as in the caption of Fig. 2.
Caption Fig 2: [...] We plot results of a psychophysiological interactions (PPI) analysis conducted using the hippocampal peak effects in (A) as a seed for low vs. high-accuracy feedback. [...]
Page 17: The estimated beta weight corresponding to the interaction term was then tested against zero on the group-level using a t-test implemented in SPM12 (Fig. 2C). The contrast reflects the difference between low vs. high-accuracy feedback. This revealed brain areas whose activity was co-varying with the hippocampus seed ROI as a function of past-trial performance (n-1).
c) It is unclear why the model testing TTC-specific / TTC-independent effects (resultspresented in Figure 3) used 2 parametric modulators (as opposed to building two separate models with a different modulator each). I wonder how the authors dealt with the orthogonalization between parametric modulators with such a model. In SPM, the orthogonalization of parametric modulators is based on the order of the modulators in the design matrix. In this case, parametric modulator #2 would be orthogonalized to the preceding modulator so that a contrast focusing on the parametric modulator #2 would highlight any modulation that is above and beyond that explained by modulator #1. In this case, modulation of brain activity that is TTC-specific would have to be above and beyond a modulation that is TTC-independent to be highlighted. I am unsure that this is what the authors wanted to test here (or whether this is how the MRI design was built). Importantly, this might bias the interpretation of their results as - by design - it is less likely to observe TTC-specific modulations in the hippocampus as there is significant TTC-independent modulation. In other words, switching the order of the modulators in the model (or building two separate models) might yield different results. This is an important point to address as this might challenge the TTC-specific/TTC-independent results described in the manuscript.
We thank the reviewer for raising this important issue. When running the respective analysis, we made sure that the regressors were not collinear and we therefore did not expect substantial overlap in shared variance between them. However, we agree with the reviewer that orthogonalizing one regressor with respect to the other could still affect the results. To make sure that our expectations were indeed met, we therefore repeated the main analysis twice: 1) switching the order of the modulators and 2) turning orthogonalization off (which is possible in SPM12 unlike in previous versions). In all cases, our key results and conclusions remained unchanged, including the central results of the hippocampus analyses.
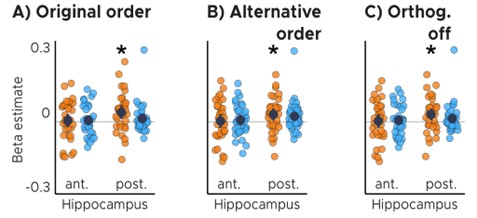
Anterior (ant.) / Posterior (post.) Hippocampus ROI analysis with A) original order of modulators, B) switching the order of the modulators and C) turning orthogonalization of modulators off. ABC) Orange color corresponds to the TTC-independent condition whereas light-blue color corresponds to the TTC-specific condition. Statistics reflect p<0.05 at Bonferroni corrected levels () obtained using a group-level one-tailed one-sample t-test against zero; A) pfwe = 0.017, B) pfwe = 0.039, C) pfwe = 0.039.*
Because orthogonalization did not affect the conclusions, the new manuscript simply reports the analysis for which it was turned off. Note that these new figures are extremely similar to the original figures we presented, which can be seen in the exemplary figure below showing our key results at a liberal threshold for transparency. In addition, we clarified that orthogonalization was turned off in the methods section as follows.
Page 18: These two regressors reflect the tests for target-TTC-independent and target-TTC-specific updating, respectively, and they were not orthogonalized to each other.
Comparison of old & new results: also see Fig. 3 and Fig. S5 in manuscript
d) It is also unclear how the behavioral improvement was coded/classified "wecontrasted trials in which participants had improved versus the ones in which they had not improved or got worse"- It appears that improvement computation was based on the change of feedback valence (between high, medium and low). It is unclear why performance wasn't used instead? This would provide a finer-grained modulation?
We thank the reviewer for the opportunity to clarify this important point. First, we chose to model feedback because it is the feedback that determines whether participants update their “internal model” or not. Without feedback, they would not know how well they performed, and we would not expect to find activity related to sensorimotor updating. Second, behavioral performance and received feedback are tightly correlated, because the former determines the latter. We therefore do not expect to see major differences in results obtained between the two. Third, we did in fact model both feedback and performance in two independent GLMs, even though the way the results were reported in the initial submission made it difficult to compare the two.
Figure 4 shows the results obtained when modeling behavioral performance in the current trial as an F-contrast, and Supplementary Fig 4 shows the results when modeling the feedback received in the current trial as a t-contrast. While the voxel-wise t-maps/F-maps are also quite similar, we now additionally report the t-contrast for the behavioral-performance GLM in a new Supplementary Figure 4C. The t-maps obtained for these two different analyses are extremely similar, confirming that the direction of the effects as well as their interpretation remain independent of whether feedback or performance is modeled.
The revised manuscript refers to the new Supplementary Figure 4C as follows.
Page 17: In two independent GLMs, we analyzed the time courses of all voxels in the brain as a function of behavioral performance (i.e. TTC error) in each trial, and as a function of feedback received at the end of each trial. The models included one mean-centered parametric regressor per run, modeling either the TTC error or the three feedback levels in each trial, respectively. Note that the feedback itself was a function of TTC error in each trial [...] We estimated weights for all regressors and conducted a t-test against zero using SPM12 for our feedback and performance regressors of interest on the group level (Fig. S4A). [...]
Page 17: In addition to the voxel-wise whole-brain analyses described above, we conducted independent ROI analyses for the anterior and posterior sections of the hippocampus (Fig. S2A). Here, we tested the beta estimates obtained in our first-level analysis for the feedback and performance regressors of interest (Fig. S4B; two-tailed one-sample t tests: anterior HPC, t(33) = -5.92, p = 1.2x10-6, pfwe = 2.4x10-6, d=-1.02, CI: [-1.45, -0.6]; posterior HPC, t(33) = -4.07, p = 2.7x10-4, pfwe = 5.4x10-4, d=-0.7, CI: [-1.09, -0.32]). See section "Regions of interest definition and analysis" for more details.
If the feedback valence was used to classify trials as improved or not, how was this modelled (one regressor for improved, one for no improvement? As opposed to a parametric modulator with performance improvement?).
We apologize for the lack of clarity regarding our regressor design. In response to this comment, we adapted the corresponding paragraph in the methods to express more clearly that improvement trials and no-improvement trials were modeled with two separate parametric regressors - in line with the reviewer’s understanding. The new paragraph reads as follows.
Page 18: One regressor modeled the main effect of the trial and two parametric regressors modeled the following contrasts: Parametric regressor 1: trials in which behavioral performance improved \textit{vs}. parametric regressor 2: trials in which behavioral performance did not improve or got worse relative to the previous trial.
Last, it is also unclear how ITI was modelled as a regressor. Did the authors mean a parametric modulator here? Some clarification on the events modelled would also be helpful. What was the onset of a trial in the MRI design? The start of the trial? Then end? The onset of the prediction time?
The Inter-trial intervals (ITIs) were modeled as a boxcar regressor convolved with the hemodynamic response function. They describe the time after the feedback-phase offset and the subsequent trial onset. Moreover, the start of the trial was the moment when the visual-tracking target started moving after the ITI, whereas the trial end was the offset of the feedback phase (i.e. the moment in which the feedback disappeared from the screen). The onset of the “prediction time” was the moment in which the visual-tracking target stopped moving, prompting participants to estimate the time-to-contact. We now explain this more clearly in the methods as shown below.
Page 16: The GLM included three boxcar regressors modeling the feedback levels, one for ITIs, one for button presses and one for periods of rest (inter-session interval, ISI), which were all convolved with the canonical hemodynamic response function of SPM12. The start of the trial was considered as the trial onsets for modeling (i.e. the time when the visual-tracking target started moving). The trial end was the offset of the feedback phase (i.e. the moment in which the feedback disappeared from the screen). The ITI was the time between the offset of the feedback-phase and the subsequent trial onset.
On a related note, in response to question 4 by reviewer 2, we now repeated one of the main analyses (Fig. 2) without modeling the ITI (as well as the Inter-session interval, ISI). We found that our key results and conclusions are independent of whether or not these time points were modeled. These new results are presented in the new Supplementary Figure 3B.
Page 16: ITIs and ISIs were modeled to reduce task-unrelated noise, but to ensure that this did not lead to over-specification of the above-described GLM, we repeated the full analysis without modeling the two. [...]
- Perhaps as a result of a lack of clarity in the result section and the MRI methods, it appears that some conclusions presented in the result section are not supported by the data. E.g. "Instead, these results are consistent with the notion that hippocampal activity signals the updating of task-relevant sensorimotor representations in real-time." The data show that hippocampal activity is higher during and after an accurate trial. This pattern of results could be attributed to various processes such as e.g. reward or learning etc. I would recommend not providing such interpretations in the result section and addressing these points in the discussion.
Similar to above, statements like "These results suggest that the hippocampus updates information that is independent of the target TTC". The data show that higher hippocampal activity is linked to greater improvement across trials independent of the timing of the trial. The point about updating is rather speculative and should be presented in the discussion instead of the result section.
The reviewer is referring to two statements in the results section that reflect our interpretation rather than a description of the results. In response to the reviewer’s comment, we therefore removed the following statement from the results.
Instead, these results are consistent with the notion that hippocampal activity signals the updating of task-relevant sensorimotor representations in real-time.
In addition, we replaced the remaining statement by the following. We feel this new statement makes clear why we conducted the analysis that is described without offering an interpretation of the results that were presented before.
Page 8: We reasoned that updating TTC-independent information may support generalization performance by means of regularizing the encoded intervals based on the temporal context in which they were encoded.
-
Evaluation Summary:
This paper is of interest to scientists interested in the functions of the hippocampus, as well as those in the field of sensorimotor timing. The reported data and findings point towards the possibility that the hippocampus supports specific and generalized learning of short time intervals relevant to behavior. While the conclusions are mostly supported by the evidence, further clarification of methodology as well as additional analyses and discussion would strengthen the authors' conclusions.
(This preprint has been reviewed by eLife. We include the public reviews from the reviewers here; the authors also receive private feedback with suggested changes to the manuscript. The reviewers remained anonymous to the authors.)
-
Reviewer #1 (Public Review):
The authors evaluate the involvement of the hippocampus in a fast-paced time-to-contact estimation task. They find that the hippocampus is sensitive to feedback received about accuracy on each trial and has activity that tracks behavioral improvement from trial to trial. Its activity is also related to a tendency for time estimation behavior to regress to the mean. This is a novel paradigm to explore hippocampal activity and the results are thus novel and important, but the framing as well as discussion about the meaning of the findings obscures the details of the results or stretches beyond them in many places, as detailed below:
Some of the results appear in the posterior hippocampus and others in the anterior hippocampus. The authors do not motivate predictions for anterior vs. posterior hippocampus, and …
Reviewer #1 (Public Review):
The authors evaluate the involvement of the hippocampus in a fast-paced time-to-contact estimation task. They find that the hippocampus is sensitive to feedback received about accuracy on each trial and has activity that tracks behavioral improvement from trial to trial. Its activity is also related to a tendency for time estimation behavior to regress to the mean. This is a novel paradigm to explore hippocampal activity and the results are thus novel and important, but the framing as well as discussion about the meaning of the findings obscures the details of the results or stretches beyond them in many places, as detailed below:
Some of the results appear in the posterior hippocampus and others in the anterior hippocampus. The authors do not motivate predictions for anterior vs. posterior hippocampus, and they do not discuss differences found between these areas in the Discussion. The hippocampus is treated as a unitary structure carrying out learning and updating in this task, but the distinct areas involved motivate a more nuanced picture that acknowledges that the same populations of cells may not be carrying out the various discussed functions.
Hippocampal activity is stronger for smaller errors, which makes the interpretation more complex than the authors acknowledge. If the hippocampus is updating sensorimotor representations, why would its activity be lower when more updating is needed?
Some tests were one-tailed without justification, which reduces confidence in the robustness of the results.
The introduction motivates the novelty of this study based on the idea that the hippocampus has traditionally been thought to be involved in memory at the scale of days and weeks. However, as is partially acknowledged later in the Discussion, there is an enormous literature on hippocampal involvement in memory at a much shorter timescale (on the order of seconds). The novelty of this study is not in the timescale as much as in the sensorimotor nature of the task.
The authors used three different regressors for the three feedback levels, as opposed to a parametric regressor indexing the level of feedback. The predictions are parametric, so a parametric regressor would be a better match, and would allow for the use of all the medium-accuracy data.
The authors claim that the results support the idea that the hippocampus is finding an "optimal trade-off between specificity and regularization". This seems overly speculative given the results presented.
The authors find that hippocampal activity is related to behavioral improvement from the prior trial. This seems to be a simple learning effect (participants can learn plenty about this task from a prior trial that does not have the exact same timing as the current trial) but is interpreted as sensitivity to temporal context. The temporal context framing seems too far removed from the analyses performed.
I am not sure the term "extraction of statistical regularities" is appropriate. The term is typically used for more complex forms of statistical relationships.
-
Reviewer #2 (Public Review):
The authors conducted a study involving functional magnetic resonance imaging and a time-to-contact estimation paradigm to investigate the contribution of the human hippocampus (HPC) to sensorimotor timing, with a particular focus on the involvement of this structure in specific vs. generalized learning. Suggestive of the former, it was found that HPC activity reflected time interval-specific improvements in performance while in support of the latter, HPC activity was also found to signal improvements in performance, which were not specific to the individual time intervals tested. Based on these findings, the authors suggest that the human HPC plays a key role in the statistical learning of temporal information as required in sensorimotor behaviour.
By considering two established functions of the HPC (i.e., …
Reviewer #2 (Public Review):
The authors conducted a study involving functional magnetic resonance imaging and a time-to-contact estimation paradigm to investigate the contribution of the human hippocampus (HPC) to sensorimotor timing, with a particular focus on the involvement of this structure in specific vs. generalized learning. Suggestive of the former, it was found that HPC activity reflected time interval-specific improvements in performance while in support of the latter, HPC activity was also found to signal improvements in performance, which were not specific to the individual time intervals tested. Based on these findings, the authors suggest that the human HPC plays a key role in the statistical learning of temporal information as required in sensorimotor behaviour.
By considering two established functions of the HPC (i.e., temporal memory and generalization) in the context of a domain that is not typically associated with this structure (i.e., sensorimotor timing), this study is potentially important, offering novel insight into the involvement of the HPC in everyday behaviour. There is much to like about this submission: the manuscript is clearly written and well-crafted, the paradigm and analyses are well thought out and creative, the methodology is generally sound, and the reported findings push us to consider HPC function from a fresh perspective. A relative weakness of the paper is that it is not entirely clear to what extent the data, at least as currently reported, reflects the involvement of the HPC in specific and generalized learning. Since the authors' conclusions centre around this observation, clarifying this issue is, in my opinion, of primary importance.
Throughout the manuscript, the authors discuss the trade-off between specific and generalized learning, and point towards Figure S1D as evidence for this (i.e., participants with higher TTC accuracy exhibited a weaker regression effect). What appears to be slightly at odds with this, however, is the observation that the deviation from true TTC decreased with time (Fig S1F) as the regression line slope approached 0.5 (Fig S1E) - one would have perhaps expected the opposite i.e., for deviation from true TTC to increase as generalization increases. To gain further insight into this, it would be helpful to see the deviation from true TTC plotted for each of the four TTC intervals separately and as a signed percentage of the target TTC interval (i.e., (+) or (-) deviation) rather than the absolute value.
Generalization relies on prior experience and can be relatively slow to develop as is the case with statistical learning. In Jazayeri and Shadlen (2010), for instance, learning a prior distribution of 11-time intervals demarcated by two briefly flashed cues (compared to 4 intervals associated with 24 possible movement trajectories in the current study) required ~500 trials. I find it somewhat surprising, therefore, that the regression line slope was already relatively close to 0.5 in the very first segment of the task. To what extent did the participants have exposure to the task and the target intervals prior to entering the scanner?
I am curious to know whether differences between high-accuracy and medium-accuracy feedback as well as between medium-accuracy and low-accuracy feedback predicted hippocampal activity in the first GLM analysis (middle page 5). Currently, the authors only present the findings for the contrast between high-accuracy and low-accuracy feedback. Examining all feedback levels may provide additional insight into the nature of hippocampal involvement and is perhaps more consistent with the subsequent GLM analysis (bottom page 6) in which, according to my understanding, all improvements across subsequent trials were considered (i.e., from low-accuracy to medium-accuracy; medium-accuracy to high-accuracy; as well as low-accuracy to high-accuracy).
The authors modelled the inter-trial intervals and periods of rest in their univariate GLMs. This approach of modelling all 'down time' can lead to model over-specification and inaccurate parameter estimation (e.g. Pernet, 2014). A comment on this approach as well as consideration of not modelling the inter-trial intervals would be useful.
-
Reviewer #3 (Public Review):
This paper reports the results of an interesting fMRI study examining the neural correlates of time estimation with an elegant design and a sensorimotor timing task. Results show that hippocampal activity and connectivity are modulated by performance on the task as well as the valence of the feedback provided. This study addresses a very important question in the field which relates to the function of the hippocampus in sensorimotor timing. However, a lack of clarity in the description of the MRI results (and associated methods) currently prevents the evaluation of the results and the interpretations made by the authors. Specifically, the model testing for timing-specific/timing-independent effects is questionable and needs to be clarified. In the current form, several conclusions appear to not be fully …
Reviewer #3 (Public Review):
This paper reports the results of an interesting fMRI study examining the neural correlates of time estimation with an elegant design and a sensorimotor timing task. Results show that hippocampal activity and connectivity are modulated by performance on the task as well as the valence of the feedback provided. This study addresses a very important question in the field which relates to the function of the hippocampus in sensorimotor timing. However, a lack of clarity in the description of the MRI results (and associated methods) currently prevents the evaluation of the results and the interpretations made by the authors. Specifically, the model testing for timing-specific/timing-independent effects is questionable and needs to be clarified. In the current form, several conclusions appear to not be fully supported by the data.
Major points
Some methodological points lack clarity which makes it difficult to evaluate the results and the interpretation of the data.
It is unclear how the 3 levels of accuracy and feedback (high, medium, and low performance) were computed. Please provide the performance range used for this classification. Was this adjusted to the participants' performance?
The description of the MRI results lacks details. It is not always clear in the results section which models were used and whether parametric modulators were included or not in the model. This makes the results section difficult to follow. For example,
a. Figure 2: According to the description in the text, it appears that panels A and B report the results of a model with 3 regressors, ie one for each accuracy/feedback level (high, medium, low) without parametric modulators included. However, the figure legend for panel B mentions a parametric modulator suggesting that feedback was modelled for each trial as a parametric modulator. The distinction between these 2 models must be clarified in the result section. Additionally, it is unclear how Figure 2A supports the following statement: "Moreover, the voxel-wise analysis revealed similar feedback-related activity in the thalamus and the striatum (Fig. 2A), and in the hippocampus when the feedback of the current trial was modeled (Fig. S3)." This is confusing as Figure 2A reports an opposite pattern of results between the striatum/thalamus and the hippocampus. It appears that the statement highlighted above is supported by results from a model including current trial feedback as a parametric modulator (reported in Figure S3). Also, note that it is unclear from Figure 2A what is the direction of the contrast highlighting the hippocampal cluster (high vs. low according to the text but the figure shows negative values in the hippocampus and positive values in the thalamus). These discrepancies need to be addressed and the models used to support the statements made in the results sections need to be explicitly described.
b. Connectivity analyses: It is also unclear here which model was used in the PPI analyses presented in Figure 2. As it appears that the seed region was extracted from a high vs. low contrast (without modulators), the PPI should be built using the same model. I assume this was the case as the authors mentioned "These co-fluctuations were stronger when participants performed poorly in the previous trial and therefore when they received low-accuracy feedback." if this refers to low vs. high contrast. Please clarify.
c. It is unclear why the model testing TTC-specific / TTC-independent effects (results presented in Figure 3) used 2 parametric modulators (as opposed to building two separate models with a different modulator each). I wonder how the authors dealt with the orthogonalization between parametric modulators with such a model. In SPM, the orthogonalization of parametric modulators is based on the order of the modulators in the design matrix. In this case, parametric modulator #2 would be orthogonalized to the preceding modulator so that a contrast focusing on the parametric modulator #2 would highlight any modulation that is above and beyond that explained by modulator #1. In this case, modulation of brain activity that is TTC-specific would have to be above and beyond a modulation that is TTC-independent to be highlighted. I am unsure that this is what the authors wanted to test here (or whether this is how the MRI design was built). Importantly, this might bias the interpretation of their results as - by design - it is less likely to observe TTC-specific modulations in the hippocampus as there is significant TTC-independent modulation. In other words, switching the order of the modulators in the model (or building two separate models) might yield different results. This is an important point to address as this might challenge the TTC-specific/TTC-independent results described in the manuscript.
d. It is also unclear how the behavioral improvement was coded/classified "we contrasted trials in which participants had improved versus the ones in which they had not improved or got worse"- It appears that improvement computation was based on the change of feedback valence (between high, medium and low). It is unclear why performance wasn't used instead? This would provide a finer-grained modulation? If the feedback valence was used to classify trials as improved or not, how was this modelled (one regressor for improved, one for no improvement? As opposed to a parametric modulator with performance improvement?). Last, it is also unclear how ITI was modelled as a regressor. Did the authors mean a parametric modulator here? Some clarification on the events modelled would also be helpful. What was the onset of a trial in the MRI design? The start of the trial? Then end? The onset of the prediction time?
Perhaps as a result of a lack of clarity in the result section and the MRI methods, it appears that some conclusions presented in the result section are not supported by the data.
E.g. "Instead, these results are consistent with the notion that hippocampal activity signals the updating of task-relevant sensorimotor representations in real-time." The data show that hippocampal activity is higher during and after an accurate trial. This pattern of results could be attributed to various processes such as e.g. reward or learning etc. I would recommend not providing such interpretations in the result section and addressing these points in the discussion.Similar to above, statements like "These results suggest that the hippocampus updates information that is independent of the target TTC". The data show that higher hippocampal activity is linked to greater improvement across trials independent of the timing of the trial. The point about updating is rather speculative and should be presented in the discussion instead of the result section.
-
