One-shot generalization in humans revealed through a drawing task
Curation statements for this article:-
Curated by eLife

Evaluation Summary:
This paper employs innovative approaches to elegantly tackle the question of how we are able to learn an object category with just a single example, and what features we use to distinguish that category. Through a collection of rigorous experiments and analytical methods, the paper demonstrates people's impressive abilities at rapid category learning and highlights the important role of distinctive features for determining category membership. This paper and its approach will be of interest to those who study learning, memory, and perception, while also contributing to a growing field which uses naturalistic drawing as a window into high-level cognition.
(This preprint has been reviewed by eLife. We include the public reviews from the reviewers here; the authors also receive private feedback with suggested changes to the manuscript. Reviewer #2 agreed to share their name with the authors.)
This article has been Reviewed by the following groups
Discuss this preprint
Start a discussion What are Sciety discussions?Listed in
- Evaluated articles (eLife)
Abstract
Humans have the amazing ability to learn new visual concepts from just a single exemplar. How we achieve this remains mysterious. State-of-the-art theories suggest observers rely on internal ‘generative models’, which not only describe observed objects, but can also synthesize novel variations. However, compelling evidence for generative models in human one-shot learning remains sparse. In most studies, participants merely compare candidate objects created by the experimenters, rather than generating their own ideas. Here, we overcame this key limitation by presenting participants with 2D ‘Exemplar’ shapes and asking them to draw their own ‘Variations’ belonging to the same class. The drawings reveal that participants inferred—and synthesized—genuine novel categories that were far more varied than mere copies. Yet, there was striking agreement between participants about which shape features were most distinctive, and these tended to be preserved in the drawn Variations. Indeed, swapping distinctive parts caused objects to swap apparent category. Our findings suggest that internal generative models are key to how humans generalize from single exemplars. When observers see a novel object for the first time, they identify its most distinctive features and infer a generative model of its shape, allowing them to mentally synthesize plausible variants.
Article activity feed
-

-

Author Response
Reviewer #1 (Public Review):
- The authors present an interesting proposal for how the generative model operates when producing shapes in Fig 6, as well as some alternative strategies in Fig 7. It is not clear what evidence supports the idea that shapes are first broken down into parts, then modified and recombined. It is obvious from the data that distinctive features are preserved (in some cases), but some clarification on the rest would be useful. For instance, is it possible that conjunctions or combinations of features are processed in concert? What determines whether critical features are added or subtracted to the shape during generation? Some more justification for this proposed model is needed, as well as for how the exceptions and alternate strategies were determined.
In line with recent eLife policy, we have …
Author Response
Reviewer #1 (Public Review):
- The authors present an interesting proposal for how the generative model operates when producing shapes in Fig 6, as well as some alternative strategies in Fig 7. It is not clear what evidence supports the idea that shapes are first broken down into parts, then modified and recombined. It is obvious from the data that distinctive features are preserved (in some cases), but some clarification on the rest would be useful. For instance, is it possible that conjunctions or combinations of features are processed in concert? What determines whether critical features are added or subtracted to the shape during generation? Some more justification for this proposed model is needed, as well as for how the exceptions and alternate strategies were determined.
In line with recent eLife policy, we have moved our discussion of how new shapes might be produced into a new subsection called ‘ideas and speculation’ to emphasise that this is a speculative proposal that goes beyond the data, rather than a straightforward report of findings per se. Such speculations are actively encouraged if appropriately flagged (see https://elifesciences.org/inside-elife/e3e52a93/elife-latest-including-ideas-and-speculation-in-elife-papers). In places, we have also reworded the description to make it clearer that our proposals are based on a qualitative assessment of the data (looking at the shapes and trying to verbalize what seemed to be going on) rather than a formal quantitative analysis.
However, our proposal is also compatible with some analyses of our data. We have added a new analysis to Experiment 4 to test whether part order has been retained or changed between Exemplars and Variations. This analysis allows us to quantify our previous observations of different strategies (cf. Fig. 7). For example, we show that there are drawings where with respect to the Exemplar the order of parts was shuffled, parts were omitted or parts were added—all pointing to a part-based recombination approach. However, we also qualified our discussion to clarify that this part-based recombination is not the only possible strategy. We have also added the reviewer’s observation that multiple parts are sometimes retained or modified in conjunction with one another.
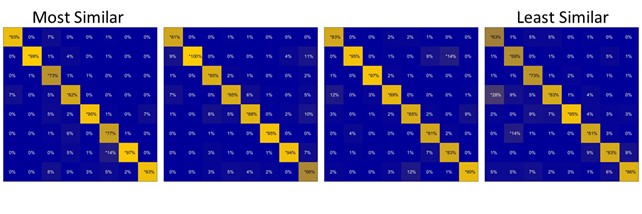
- Some claims are made in the manuscript about large changes being made to Variations without consequence to effective categorization. However, these appeal to findings derived from collapsing across all Variations, when it could be informative to investigate the edge cases in more detail. There is a broad range in the similarity of Variations to Exemplars, and this could have been profitably considered in some analyses, especially zooming in on the 'Low Similarity' Variations. For example, this would help determine whether classification performance and the confusion matrix change in predictable ways for high-, relative to medium- and low-similarity Variations. It could also indicate whether the features and feature overlap can tell us anything about how likely a Variation is to be perceived as from the correct category.
To address this point, we have added a new analysis to Experiment 3, which compares the classification performance across 4 similarity bins (from low- to high-similarity). This reveals that performance remained high—indeed virtually identical—for the three ‘most similar’ bins. Only the ‘least similar’ bin showed a slightly reduced performance, albeit, still at a low level of mis-classifications. We now describe this analysis and the results in the text; here, we additionally show the confusion matrices per similarity bin.
- The authors cross-referenced data from Experiments 4 and 5 to draw the conclusion that the most distinct features are preserved in Variations. This was very compelling and raised the idea that there are further opportunities to perform cross-experiment comparisons to better support the existing claims. For example, perhaps the correspondence percentages in Exp 4, or the 'distinctive feature-ness' in E5, allow prediction of the confusion proportions in Exp 3.
Thanks for this suggestion. We have added a new subplot to Fig S 2 showing that the average percentage of area decreases as a function of decreasing similarity to the Exemplar. We now also report this result in the text (Experiment 4).
- The Variation generation task did not require any explicit discrimination between objects to establish category learning, which is a strength of the work that the authors highlighted. However, it's worth considering that discrimination may have had some lingering impact on Variation generation, given that participants were tasked with generating Variations for multiple exemplars. Specifically, when they are creating Variations for Exemplar B after having created Variations for Exemplar A, are they influenced both by trying to generate something that is very like Exemplar B but also something that is decidedly not like Exemplar A? A prediction that logically follows from this would be that there are order effects, such that metrics of feature overlap and confusion across categories decreases for later Exemplars.
We now discuss potential carry-over effects in Experiment 1, together with how we tried to minimize these effects by randomizing the order of Exemplars per participant. We also added to the discussion section how future studies might use crowd-sourcing with only a single Exemplar to completely eliminate such effects.
In an additional analysis not reported in the study we find that the ‘age’ of a drawing (i.e., whether it was drawn earlier or later in the experiment) is not significantly correlated to the percentage of correct categorizations in Experiment 3 (r = -0.04). Although this does not rule out carry-over effects completely, it does suggest that they did not significantly affect categorization decisions.
Reviewer #2 (Public Review):
Overall, I find the paper compelling, the experiments methodologically rigorous, and the results clear and impactful. By using naïve online observers, the researchers are able to make compelling arguments about the generalizability of their effects. And, by creative methods such as swapping out the distinctive (vs. less distinctive) features and then testing categorization, they are able to successfully pinpoint some of the determinants of one-shot learning.
We would like to clarify that all experiments were done in person and not over the internet, as reviewer #2 mentioned “naive online observers” in a comment. After carefully checking the text we could find no mention of online experiments.
-
Evaluation Summary:
This paper employs innovative approaches to elegantly tackle the question of how we are able to learn an object category with just a single example, and what features we use to distinguish that category. Through a collection of rigorous experiments and analytical methods, the paper demonstrates people's impressive abilities at rapid category learning and highlights the important role of distinctive features for determining category membership. This paper and its approach will be of interest to those who study learning, memory, and perception, while also contributing to a growing field which uses naturalistic drawing as a window into high-level cognition.
(This preprint has been reviewed by eLife. We include the public reviews from the reviewers here; the authors also receive private feedback with suggested changes to …
Evaluation Summary:
This paper employs innovative approaches to elegantly tackle the question of how we are able to learn an object category with just a single example, and what features we use to distinguish that category. Through a collection of rigorous experiments and analytical methods, the paper demonstrates people's impressive abilities at rapid category learning and highlights the important role of distinctive features for determining category membership. This paper and its approach will be of interest to those who study learning, memory, and perception, while also contributing to a growing field which uses naturalistic drawing as a window into high-level cognition.
(This preprint has been reviewed by eLife. We include the public reviews from the reviewers here; the authors also receive private feedback with suggested changes to the manuscript. Reviewer #2 agreed to share their name with the authors.)
-
Reviewer #1 (Public Review):
Tiedemann et al. investigated internal generative models as a mechanistic explanation of one-shot learning of visual categories. To achieve this, they designed a clever paradigm where participants draw new Variations of a category based on a single presented shape (the Exemplar). They found that participants could successfully generate new Variations based on an Exemplar (Exp 1), that these vary in Similarity to the Exemplar (Exp 2), and are more than just mere copies of the Exemplar (Exp 2b). Next, they demonstrated that Variations are readily attributed to the correct corresponding Exemplar 'category' by naïve participants (Exp 3). Having established that novel Variations in a category can be generated as a result of one-shot learning, the authors turned to establishing what features drive these novel …
Reviewer #1 (Public Review):
Tiedemann et al. investigated internal generative models as a mechanistic explanation of one-shot learning of visual categories. To achieve this, they designed a clever paradigm where participants draw new Variations of a category based on a single presented shape (the Exemplar). They found that participants could successfully generate new Variations based on an Exemplar (Exp 1), that these vary in Similarity to the Exemplar (Exp 2), and are more than just mere copies of the Exemplar (Exp 2b). Next, they demonstrated that Variations are readily attributed to the correct corresponding Exemplar 'category' by naïve participants (Exp 3). Having established that novel Variations in a category can be generated as a result of one-shot learning, the authors turned to establishing what features drive these novel categories. To this end, they asked naïve participants to view pairings of a single Exemplar and Variation, and label overlapping features (Exp 4), or to view single Exemplars or Variations and label their distinctive parts (Exp 5). The authors find that each shape had distinctive features that were reliably reported across participants, that most features were shared among an Exemplar and its Variations, and that few features were shared with Variations of other Exemplars. To confirm the importance of these distinctive features, shapes were produced where the distinctive parts from two shapes were traded. Naïve participants sorting decisions now appeared to be biased toward the Exemplar that matched the swapped-in diagnostic feature, not the remainder of the shape (Exp 6).
These experiments were thoroughly run, they establish a rich basis for exploring one-shot learning, provide novel methodological approaches for quantifying information about complex shape comparisons, and contribute to our understanding of how novel categories can be extrapolated from individual objects - through internal generation driven by distinctive features. The conclusions drawn here are mostly consistent with what the data demonstrated, though could use some clarification and further justification. There are some instances where within- and across-experiment comparisons could have been used to drive further insights, allowing some of the proposed mechanisms to be clarified and better supported.
The authors present an interesting proposal for how the generative model operates when producing shapes in Fig 6, as well as some alternative strategies in Fig 7. It is not clear what evidence supports the idea that shapes are first broken down into parts, then modified and recombined. It is obvious from the data that distinctive features are preserved (in some cases), but some clarification on the rest would be useful. For instance, is it possible that conjunctions or combinations of features are processed in concert? What determines whether critical features are added or subtracted to the shape during generation? Some more justification for this proposed model is needed, as well as for how the exceptions and alternate strategies were determined.
Some claims are made in the manuscript about large changes being made to Variations without consequence to effective categorization. However, these appeal to findings derived from collapsing across all Variations, when it could be informative to investigate the edge cases in more detail. There is a broad range in the similarity of Variations to Exemplars, and this could have been profitably considered in some analyses, especially zooming in on the 'Low Similarity' Variations. For example, this would help determine whether classification performance and the confusion matrix change in predictable ways for high-, relative to medium- and low-similarity Variations. It could also indicate whether the features and feature overlap can tell us anything about how likely a Variation is to be perceived as from the correct category.
The authors cross-referenced data from Experiments 4 and 5 to draw the conclusion that the most distinct features are preserved in Variations. This was very compelling and raised the idea that there are further opportunities to perform cross-experiment comparisons to better support the existing claims. For example, perhaps the correspondence percentages in Exp 4, or the 'distinctive feature-ness' in E5, allow prediction of the confusion proportions in Exp 3.
The Variation generation task did not require any explicit discrimination between objects to establish category learning, which is a strength of the work that the authors highlighted. However, it's worth considering that discrimination may have had some lingering impact on Variation generation, given that participants were tasked with generating Variations for multiple exemplars. Specifically, when they are creating Variations for Exemplar B after having created Variations for Exemplar A, are they influenced both by trying to generate something that is very like Exemplar B but also something that is decidedly not like Exemplar A? A prediction that logically follows from this would be that there are order effects, such that metrics of feature overlap and confusion across categories decreases for later Exemplars.
-
Reviewer #2 (Public Review):
This study explores people's ability to perform one shot generalization - forming a category representation with just a single exemplar - and what features contribute to these categories. In order to avoid the biases that come with forced-choice discrimination tasks, the study employs an innovative drawing method, where participants see a single exemplar and then have to generate variations from the same inferred category. Then with a series of elegant online experiments, the study finds that these variations are successfully perceived as being from the same category by others, and that it is the most distinctive object parts (as well as curvature) that best delineate the object categories.
Overall, I find the paper compelling, the experiments methodologically rigorous, and the results clear and impactful. …
Reviewer #2 (Public Review):
This study explores people's ability to perform one shot generalization - forming a category representation with just a single exemplar - and what features contribute to these categories. In order to avoid the biases that come with forced-choice discrimination tasks, the study employs an innovative drawing method, where participants see a single exemplar and then have to generate variations from the same inferred category. Then with a series of elegant online experiments, the study finds that these variations are successfully perceived as being from the same category by others, and that it is the most distinctive object parts (as well as curvature) that best delineate the object categories.
Overall, I find the paper compelling, the experiments methodologically rigorous, and the results clear and impactful. By using naïve online observers, the researchers are able to make compelling arguments about the generalizability of their effects. And, by creative methods such as swapping out the distinctive (vs. less distinctive) features and then testing categorization, they are able to successfully pinpoint some of the determinants of one-shot learning.
-
Reviewer #3 (Public Review):
In this manuscript, the authors aim to determine the mechanisms by which people generalize from novel shapes to categories of shapes. They showed participants novel shapes and asked them to draw a new object from the same category. A separate group of participants then categorized the drawn shapes. Exchanging distinctive parts between the exemplars and categorizing these chimeric shapes proved that the most distinctive parts were mainly responsible for assigning category membership.
This set of experiments is well conceived, executed, and analyzed. The manipulations are sensible, the construction of the chimeric shapes is an interesting concept, and the results are convincing. Specifically, the comparison between swapping the most versus the least distinctive part provides for a convincing control condition. …
Reviewer #3 (Public Review):
In this manuscript, the authors aim to determine the mechanisms by which people generalize from novel shapes to categories of shapes. They showed participants novel shapes and asked them to draw a new object from the same category. A separate group of participants then categorized the drawn shapes. Exchanging distinctive parts between the exemplars and categorizing these chimeric shapes proved that the most distinctive parts were mainly responsible for assigning category membership.
This set of experiments is well conceived, executed, and analyzed. The manipulations are sensible, the construction of the chimeric shapes is an interesting concept, and the results are convincing. Specifically, the comparison between swapping the most versus the least distinctive part provides for a convincing control condition. The use of confusion matrices for the categorization experiment allows for the analysis of specific mis-classifications. All stimuli are publicly available.
-
